Claude Sonnet보다 코드를 더 잘 짜는 AI를 16분의 1 비용으로 돌렸습니다 — ATLAS
60만 원짜리 GPU(RTX 5060 Ti)에서 14B 오픈소스 모델을 돌리면 Claude Sonnet보다 코딩 정확도가 높고 비용은 16분의 1입니다. ATLAS V3의 3단계 파이프라인과 벤치마크 결과를 분석합니다.
Claude Sonnet API로 코드를 짜면 건당 88원입니다. 그런데 60만 원짜리 그래픽카드(RTX 5060 Ti) 하나에 무료 AI 모델을 올려서 같은 일을 시키면 건당 5원이고, 정확도는 오히려 더 높습니다.
오픈소스 프로젝트 ATLAS V3가 LiveCodeBench(전 세계 AI 코딩 능력을 측정하는 표준 벤치마크)에서 74.6%를 기록하며, Claude 4.5 Sonnet의 71.4%를 넘었습니다. 비용은 16분의 1, 데이터는 내 컴퓨터 밖으로 나가지 않습니다.

숫자로 보는 비교 — ATLAS vs 클라우드 AI
ATLAS V3는 Qwen3-14B라는 140억 개 파라미터 오픈소스 모델을 사용합니다. 이 모델을 4비트로 압축(양자화)해서 16GB 그래픽카드 메모리에 올린 뒤, 3단계 파이프라인으로 성능을 끌어올립니다.
벤치마크는 LiveCodeBench v5입니다. LeetCode, AtCoder, Codeforces 같은 코딩 대회 사이트에서 문제를 모아 AI의 코드 작성 능력을 측정합니다. 총 599개 문제로, AI가 한 번에 정답 코드를 생성하는 비율(pass@1)을 측정합니다.
표에서 보이듯, DeepSeek V3.2가 점수도 가장 높고 비용도 가장 저렴합니다. ATLAS는 전체 1위가 아닙니다. 하지만 핵심은 이것입니다: 내 컴퓨터에서 무료 모델로 돌린 결과가 건당 88원짜리 유료 API를 이기고 있다는 사실. 특히 코드 데이터가 외부 서버로 전송되지 않는다는 점은 보안이 중요한 환경에서 큰 장점입니다.
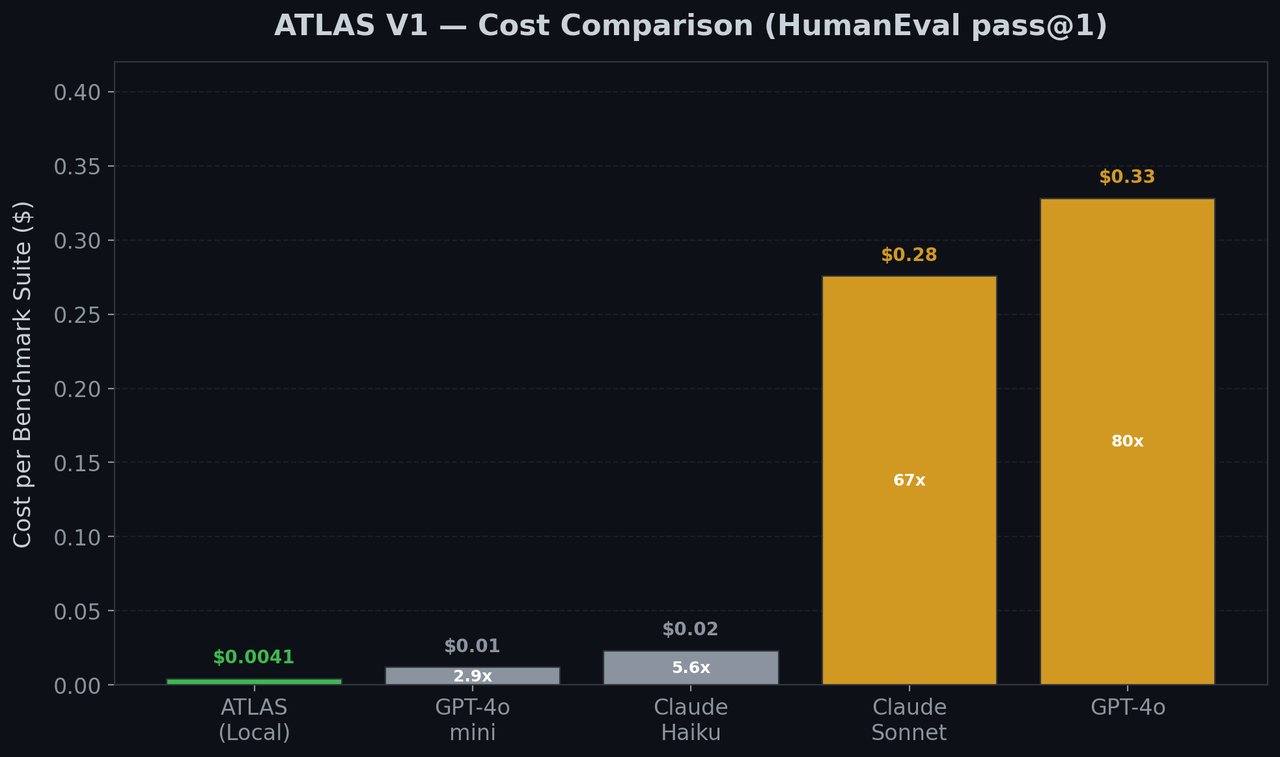
위 차트는 V1 기준(HumanEval 벤치마크)이며, V3에서는 LiveCodeBench 기준으로 측정했습니다. 방향은 동일합니다 — 로컬 실행 비용이 클라우드 API 대비 압도적으로 저렴합니다.
60만 원짜리 GPU가 클라우드 API를 이기는 비결
비결은 "테스트 시간 연산 최적화"(test-time compute optimization)입니다. 쉽게 말하면, AI가 답을 바로 내놓는 대신 여러 번 깊이 생각하고, 직접 실행해보고, 틀리면 고치는 과정을 거치게 하는 것입니다.
사람에 비유하면 이렇습니다. 시험 문제를 받으면 바로 답을 적는 게 아니라, 3가지 풀이법으로 각각 풀어본 뒤 가장 좋은 답을 고르고, 검산까지 하는 것입니다.
1단계: 3가지 풀이를 동시에 만든다 (+12.4%p 향상)
보통 AI는 한 문제에 하나의 답을 냅니다. ATLAS는 PlanSearch라는 기법으로 문제의 제약 조건을 분석한 뒤, 서로 다른 전략으로 3개의 코드를 동시에 생성합니다. 그중 가장 좋은 것을 고릅니다. 이 단계만으로 기본 정확도 54.9%가 67.3%로 올라갑니다.
2단계: 코드를 직접 실행해서 검증한다
생성된 3개의 코드를 샌드박스(격리된 안전한 실행 환경)에서 실제로 돌려봅니다. 실행이 되는지, 기대한 결과가 나오는지 확인합니다. 현재 버전에서 이 단계의 "지능형 후보 선별" 기능은 학습 데이터 부족(60개)으로 추가 성능 기여가 0%p이지만, 기본 검증은 작동합니다.
3단계: 실패하면 스스로 테스트를 만들어 수정한다 (+7.3%p 향상)
3개의 코드가 모두 틀리면 포기하지 않습니다. AI가 자체적으로 테스트 케이스를 생성해서 어디가 틀렸는지 찾고, PR-CoT(다중 관점 추론 체인)으로 코드를 고칩니다. 이 과정으로 실패한 문제 194개 중 42개(21.6%)를 구제합니다.
이 3단계를 합치면 기본 모델(54.9%)에서 74.6%까지, 약 20%p가 올라갑니다. 모델 자체를 재학습(파인튜닝)하지 않고, 추론 과정만 바꿔서 이 정도 향상을 달성한 것입니다.
솔직한 한계 — 이것만은 알고 쓰세요
ATLAS V3는 흥미로운 실험이지만, 만능은 아닙니다. 정직하게 짚어야 할 점들이 있습니다.
1. 벤치마크에 맞춰 최적화됐습니다. V3 파이프라인은 LiveCodeBench에 맞춰 설계됐다고 개발자가 직접 밝혔습니다. 실무에서 마주하는 다양한 코딩 과제(웹 개발, 데이터 처리, 시스템 프로그래밍 등)에서도 같은 성능이 나온다고 보기는 어렵습니다.
2. DeepSeek V3.2가 더 좋고 더 쌉니다. 86.2% 정확도에 문제당 3원이면 ATLAS보다 모든 면에서 앞섭니다. 다만 DeepSeek는 클라우드 서비스라 코드 데이터가 외부로 전송됩니다. 보안이 중요하다면 로컬 실행이 유리합니다.
3. 개인 프로젝트입니다. GitHub 스타 155개의 개인 개발자 프로젝트입니다. 대규모 팀이 유지보수하는 제품이 아니므로, 프로덕션 환경에 바로 적용하기보다는 실험과 학습 목적으로 접근하는 것이 좋습니다.
4. 순차 처리만 됩니다. 한 번에 한 문제만 처리합니다. 빠른 응답이 필요한 실시간 코딩 보조(Copilot 같은)에는 적합하지 않습니다.
직접 돌려보고 싶다면 — 5분 설치 가이드
필요한 하드웨어:
- GPU: 16GB VRAM 이상 — RTX 5060 Ti 16GB(약 57만 원), RTX 4060 Ti 16GB(약 50만 원), RTX 3090(약 80만 원 중고) 등
- 시스템 RAM: 14GB 이상
- OS: Ubuntu 24 또는 RHEL 9
- Python 3.10 이상
# 1. 저장소 복제
git clone https://github.com/itigges22/ATLAS.git && cd ATLAS
# 2. 설정 파일 준비
cp atlas.conf.example atlas.conf
# 3. 의존성 설치 (Qwen3-14B 모델 자동 다운로드 포함)
sudo ./scripts/install.sh
# 4. 설치 확인
./scripts/verify-install.sh
# 5. 벤치마크 실행
python3 benchmark/v3_runner.pyRTX 5060 Ti 16GB는 NVIDIA에서 $429(약 57만 원)에 출시한 소비자용 그래픽카드입니다. 2025년 4월 출시 후 현재까지 꾸준히 공급되고 있으며, AI 모델 로컬 실행에 필요한 16GB VRAM을 갖추고 있습니다.
"작은 모델이 똑똑하게 생각하는 시대"가 온다
ATLAS가 중요한 이유는 점수 자체가 아닙니다. 작은 모델 + 똑똑한 파이프라인 = 비싼 클라우드 API를 이길 수 있다는 것을 실제 벤치마크로 증명했기 때문입니다.
이것은 AI 업계의 큰 흐름과 맞닿아 있습니다. 더 큰 모델을 훈련하는 대신, 이미 있는 작은 모델을 추론 시점에 더 똑똑하게 쓰는 기술이 빠르게 발전하고 있습니다. 지난주 소개한 TurboQuant이 메모리를 6분의 1로 줄이는 기술이었다면, ATLAS는 같은 모델의 정확도를 20%p 끌어올리는 기술입니다. 방향은 같습니다 — AI를 내 컴퓨터에서 실용적으로 돌리는 시대가 가까워지고 있습니다.
ATLAS 개발자는 V3.1에서 80~90% 정확도를 목표로 하고 있습니다. Qwen3.5-9B 모델 업그레이드, 2단계 재설계, 불필요한 기능 제거가 계획돼 있습니다. 155개의 스타로 시작한 프로젝트가 어디까지 갈 수 있을지 지켜볼 만합니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기
출처