TurboQuant — AI 메모리 압축 6배·속도 8배, 정확도 손실 제로 (Google·KAIST)
Google·KAIST가 공동 개발한 TurboQuant — AI KV 캐시를 3비트로 압축해 메모리 6분의 1, H100 속도 8배 향상. 정확도 손실 0%, 파인튜닝 불필요. ICLR 2026 발표 예정. 내 AI가 빨라지는 이유를 확인하세요.
Google Research와 한국 KAIST가 함께 만든 AI 압축 기술 TurboQuant이 공개됐습니다. AI가 대화하면서 기억하는 데 쓰는 KV 캐시(Key-Value Cache) 메모리를 6분의 1로 줄이고, 응답 속도를 8배까지 높이면서도 정확도는 전혀 떨어지지 않습니다. TechCrunch는 이 기술을 두고 "실리콘밸리 드라마의 파이드 파이퍼가 현실이 됐다"고 표현했고, 해커뉴스에서는 하루 만에 497표를 받으며 뜨거운 관심을 끌고 있습니다.

AI LLM 압축 혁신 — 실리콘밸리 '파이드 파이퍼'가 현실이 됐습니다
HBO 드라마 실리콘밸리에서 주인공 리처드 헨드릭스가 만든 '파이드 파이퍼'는 데이터를 극단적으로 압축하는 가상의 알고리즘이었습니다. 2026년 3월, Google Research가 발표한 TurboQuant를 본 인터넷 커뮤니티는 "파이드 파이퍼가 현실이 됐다"고 반응했습니다.
과장은 아닙니다. TurboQuant는 AI가 대화를 이어가면서 '아까 뭐라고 했지?'를 기억하는 공간인 KV 캐시(Key-Value Cache)를 기존 32비트에서 단 3비트로 압축합니다. 숫자 하나를 표현하는 데 32칸이 필요했던 것을 3칸으로 줄인 셈입니다. 그런데 AI의 대답 품질은 전혀 떨어지지 않습니다.
• 메모리 사용량: 6분의 1로 감소 (긴 문맥 검색 기준)
• 응답 속도: H100 GPU에서 최대 8배 향상
• 정확도 손실: 0 — 학습(파인튜닝)도 필요 없음
3비트로 충분한 이유 — TurboQuant KV 캐시 압축 알고리즘 원리
왜 3비트만으로 32비트와 같은 정확도를 낼 수 있을까요? TurboQuant는 두 단계로 작동합니다.
1단계 — 방향만 기억합니다 (PolarQuant)
서울에서 부산까지 가는 길을 기록한다고 생각해보겠습니다. GPS 좌표 수천 개를 저장하는 대신 "남쪽으로 330km"라고만 적어도 충분합니다. TurboQuant의 첫 번째 단계인 PolarQuant(AISTATS 2026 발표 예정)가 바로 이 원리입니다.
기존 방식은 X축, Y축, Z축처럼 직각 좌표(Cartesian)를 사용해 AI의 기억을 저장했습니다. PolarQuant는 이걸 극좌표(Polar)로 변환합니다. 즉, '어느 방향으로 얼마나 멀리'라는 형식으로 바꾸는 것입니다. 이렇게 하면 데이터의 패턴이 훨씬 단순해져서, 적은 비트로도 핵심 정보를 정확히 담을 수 있습니다.
2단계 — 나머지 오차는 1비트로 잡습니다 (QJL)
1단계에서 대부분의 정보를 압축한 뒤, 아주 작은 오차가 남습니다. 여기서 QJL(Quantized Johnson-Lindenstrauss) 알고리즘이 등장합니다. 남은 오차를 +1 또는 -1, 즉 1비트만으로 보정합니다. 수학적으로 증명된 '균형 추정기(balancing estimator)'를 사용하기 때문에, 이 1비트 보정만으로 오차가 완전히 사라집니다.
결과적으로 2비트(PolarQuant) + 1비트(QJL) = 총 3비트로 32비트와 동일한 정확도를 달성합니다.
H100 GPU 속도 8배·메모리 6분의 1 감소 — TurboQuant LLM 벤치마크
Google Research 팀은 Llama-3.1-8B, Gemma, Mistral 등 주요 오픈소스 AI 모델에서 TurboQuant를 테스트했습니다.
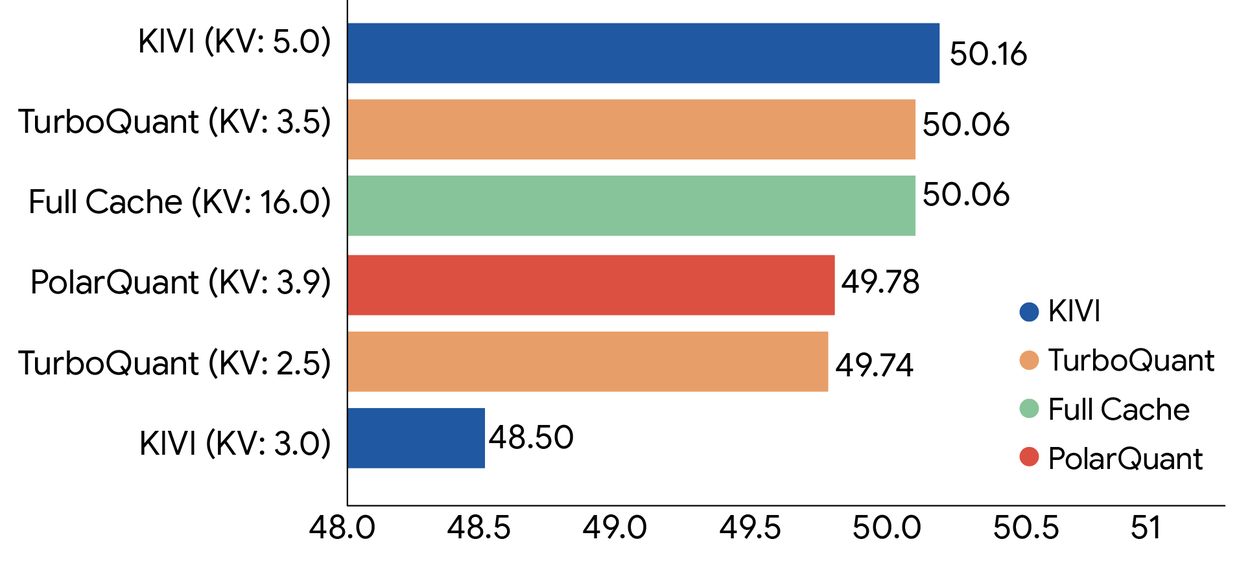
LongBench, RULER, L-Eval, ZeroSCROLLS 등 긴 문맥을 다루는 벤치마크에서 3비트 TurboQuant는 원본(32비트)과 사실상 동일한 성능을 보여줬습니다. 특히 '바늘 찾기(needle-in-haystack)' 테스트 — AI에게 긴 문서를 주고 특정 정보를 찾게 하는 실험 — 에서 메모리를 6분의 1로 줄이고도 정확도를 유지했습니다.
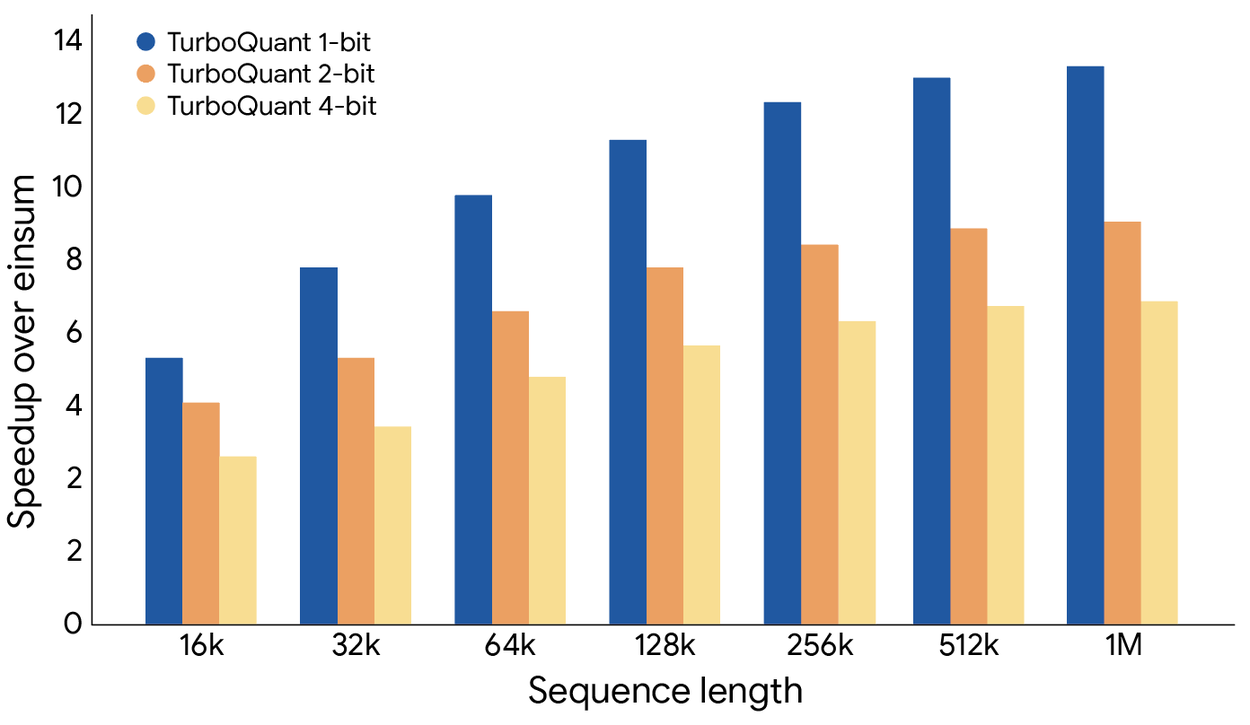
속도 면에서는 NVIDIA H100 GPU에서 4비트 TurboQuant가 32비트 원본 대비 최대 8배 빠른 어텐션(attention) 연산을 달성했습니다. 이건 AI가 '생각하는 과정' 자체가 8배 빨라졌다는 의미입니다.
도서관에서 책을 찾는다고 생각해보겠습니다. 기존 AI는 책장 6개를 전부 뒤져야 원하는 정보를 찾았습니다. TurboQuant를 쓰면 책장 1개만 확인하면 됩니다. 그런데 찾는 정확도는 똑같습니다. 게다가 책장을 넘기는 속도가 8배 빨라졌습니다.
KAIST에서 Google까지 — 한국 연구자 한인수의 이름이 있습니다
TurboQuant 논문의 공동 저자 목록에 한인수(Insu Han) KAIST 연구원이 포함되어 있습니다. Google DeepMind의 Majid Hadian, NYU의 Majid Daliri, 그리고 Google Research의 Amir Zandieh와 Vahab Mirrokni 등이 함께 참여했습니다.
한국 연구자가 세계 최대 AI 기업의 핵심 인프라 기술 개발에 공동 저자로 참여한 것은, 한국 AI 연구 역량이 글로벌 수준에 있다는 것을 보여주는 사례입니다. TurboQuant는 ICLR 2026(세계 최고 수준의 AI 학회)에서 정식 발표될 예정이고, 기반 기술인 PolarQuant는 AISTATS 2026에서 발표됩니다.
ChatGPT·Claude 등 AI 서비스가 빨라지는 시점
TurboQuant는 아직 연구 단계이고, 공개된 코드 저장소는 없습니다. 하지만 이 기술이 실제 서비스에 적용되면 우리가 매일 쓰는 AI에 큰 변화가 올 수 있습니다.
• 클라우드 AI 서비스 — ChatGPT, Claude 등의 운영 비용이 절감되면 구독료 인하나 무료 사용량 확대로 이어질 수 있습니다
• 로컬 AI — Ollama(내 컴퓨터에서 AI를 돌리는 도구) 같은 프로그램에 적용되면, 같은 그래픽카드로 6배 더 긴 대화를 처리할 수 있습니다
• AI 검색 — Google이 TurboQuant를 자사 검색 엔진(Gemini)에 먼저 적용할 가능성이 높습니다
VentureBeat는 "AI 인프라 비용을 50% 이상 절감할 수 있다"고 분석했습니다. Tom's Hardware는 "NVIDIA H100에서 KV 캐시를 3비트로 압축해 정확도 손실 없이 성능을 끌어올렸다"고 보도했습니다.
이런 AI 인프라 혁신이 실생활에 어떤 변화를 가져오는지 더 알고 싶다면, 에이전틱 AI 입문 가이드에서 AI가 자율적으로 작동하는 원리와 활용법을 확인해보세요.
논문 원문은 arXiv에서 확인할 수 있습니다: TurboQuant 논문 | PolarQuant 논문
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기
출처