로컬 AI 문서 검색 시스템 구축 — Ollama RAG 7주 무료 강좌
깃허브 스타 4,600개 돌파한 무료 RAG 강좌. Ollama·OpenSearch·LangGraph로 사내 문서 AI 검색 시스템을 내 컴퓨터에서 7주 만에 구축합니다. 외부 API 비용 0원, 텔레그램 봇까지 완성.
• 내 코드를 지키는 보안 도구가 오히려 비밀번호를 훔쳤습니다 — Trivy 해킹 사건
• tinybox Red v2 — 1600만 원으로 클라우드 없이 로컬 AI 무제한
• Screenpipe — 화면·음성 24시간 로컬 AI 기록, Microsoft Recall 대안 오픈소스
회사에서 ChatGPT를 쓰고 싶지만, 기밀 문서를 외부 서버에 올릴 수는 없습니다. 이 문제를 해결하는 핵심이 바로 로컬 AI 기반 RAG(검색 증강 생성) 시스템입니다. Production Agentic RAG Course는 Ollama 등 무료 도구만으로 사내 문서 AI 검색 시스템을 내 컴퓨터에서 처음부터 끝까지 만드는 7주 무료 오픈소스 강좌로, 깃허브 스타 4,600개를 돌파하며 주목받고 있습니다.
- 깃허브 스타 4,600개, 포크 1,200개 — 실무자들이 실제로 따라 하고 있는 강좌
- ChatGPT·Claude 같은 외부 API 없이, Ollama(내 컴퓨터에서 돌아가는 무료 AI)만으로 완성
- 7주 뒤에는 텔레그램 봇으로 어디서든 사내 문서를 검색하는 시스템이 만들어짐
로컬 AI 문서 검색이 필요한 이유
AI에게 회사 문서를 물어보고 싶을 때 가장 먼저 떠오르는 건 ChatGPT입니다. 하지만 고객 데이터, 재무 보고서, 내부 매뉴얼을 외부 서버에 올리는 순간 정보 유출 위험이 생깁니다. 실제로 삼성전자가 ChatGPT 사용을 금지한 것도 같은 이유였습니다.
RAG(검색 증강 생성)는 이 문제의 해법입니다. 쉽게 말해, AI에게 질문하면 먼저 내 문서에서 관련 내용을 찾고, 그 내용을 바탕으로 답변을 만드는 방식입니다. 데이터가 내 컴퓨터를 벗어나지 않으니 보안 걱정이 없습니다.
문제는 이걸 실제로 만들려면 검색 엔진, 데이터베이스, AI 모델, 파이프라인을 전부 연결해야 한다는 것입니다. 이 강좌가 바로 그 과정을 7주에 걸쳐 한 단계씩 안내합니다.
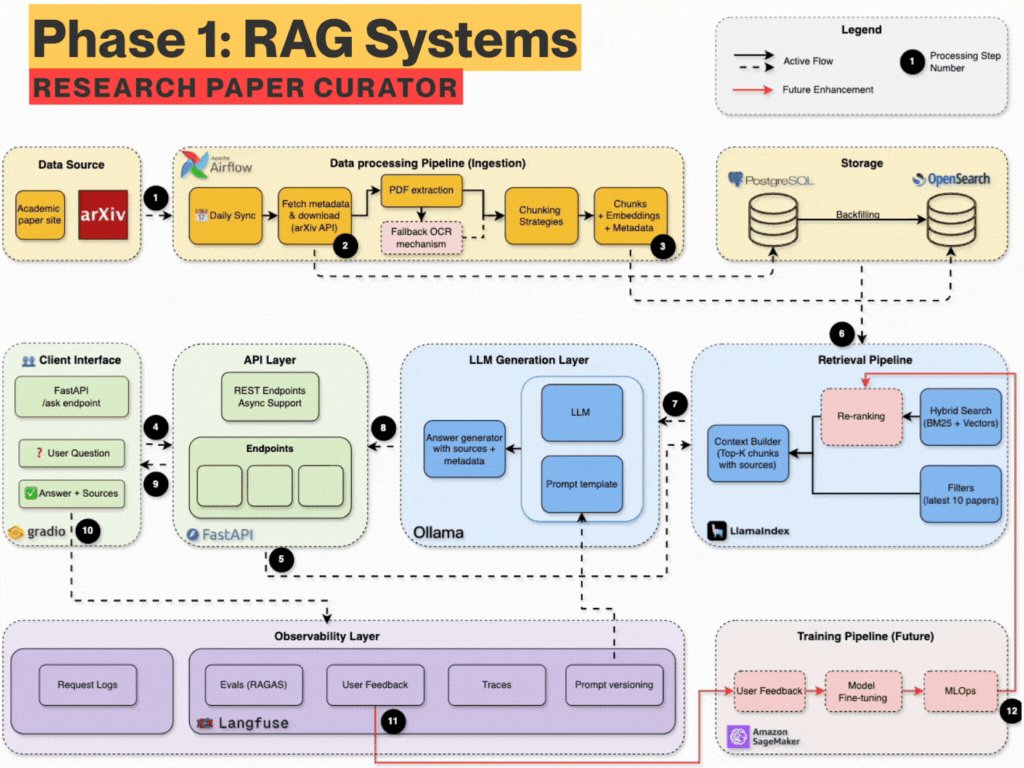
RAG 시스템 7주 커리큘럼 — 매주 무엇을 만드는가
Docker 한 줄 명령어로 AI 서버(Ollama), 검색 엔진(OpenSearch), 데이터베이스(PostgreSQL), API 서버(FastAPI)를 한꺼번에 띄웁니다. 각 서비스가 정상인지 자동으로 확인하는 헬스체크까지 포함됩니다.
arXiv(AI 논문 저장소)에서 논문을 자동으로 가져오고, PDF를 파싱해서 텍스트를 추출합니다. Apache Airflow로 매일 자동 수집되는 파이프라인을 만듭니다.
BM25 알고리즘(구글 검색의 기초가 되는 방식)으로 문서 검색을 구현합니다. 이 강좌의 철학은 "AI를 붙이기 전에 검색부터 제대로 만들자"입니다. 실제 기업들도 이 순서로 시스템을 구축합니다.
키워드 검색에 AI 임베딩(텍스트를 AI가 이해하는 숫자로 변환)을 결합합니다. "머신러닝"을 검색하면 "기계학습"이라고 적힌 문서도 찾아주는 것이 핵심입니다. Jina AI의 무료 임베딩을 사용합니다.
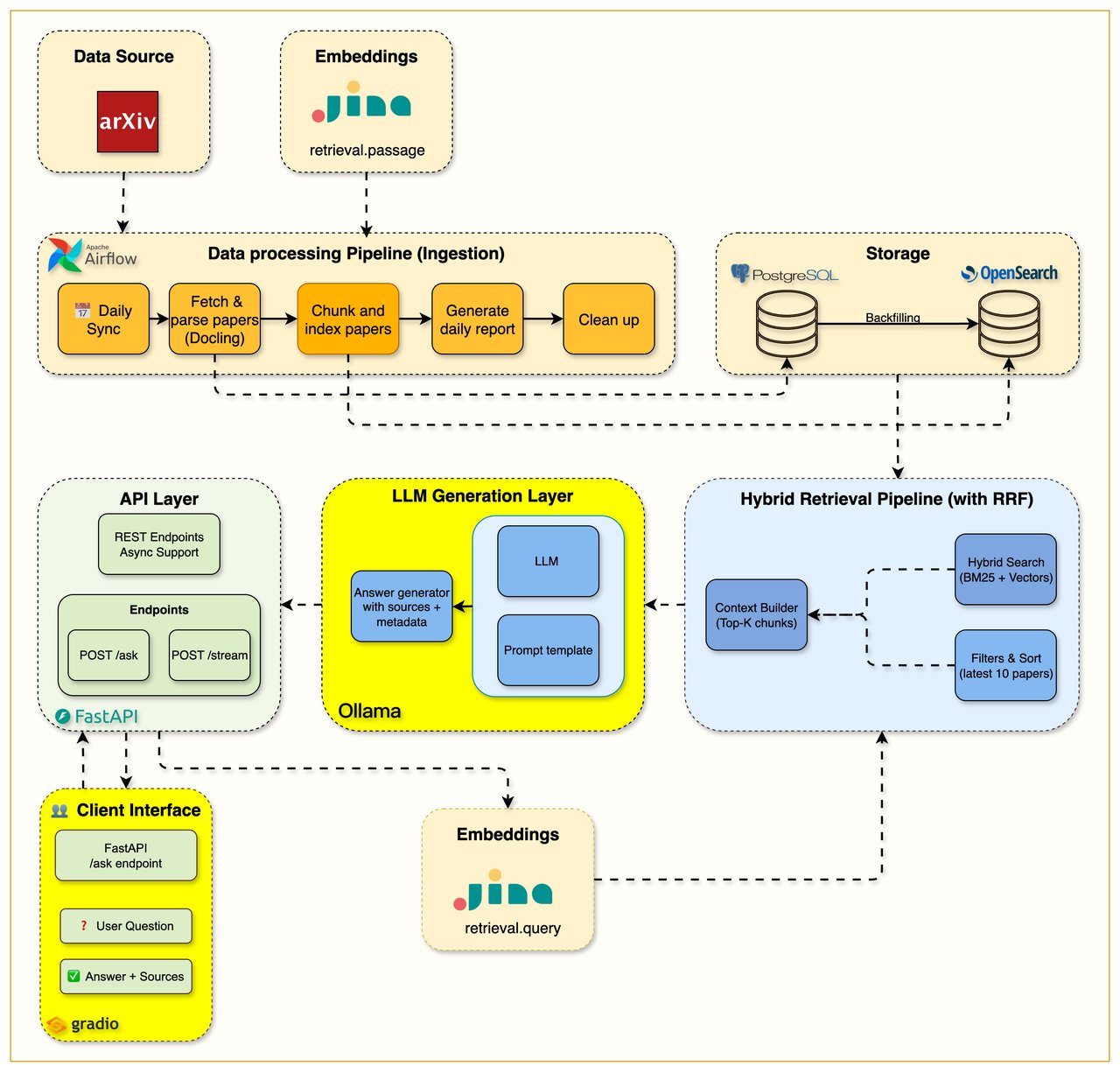
Ollama에서 돌아가는 로컬 AI 모델과 검색 시스템을 연결합니다. 질문하면 관련 문서를 찾고 → AI가 답변을 생성하고 → 출처까지 표시합니다. 프롬프트 최적화로 토큰 사용량을 80% 줄이는 기법도 배웁니다.
Langfuse로 AI가 어떤 문서를 참고해서 답변했는지 추적하고, Redis 캐싱으로 같은 질문에 즉시 응답하게 만듭니다. 운영 환경에서 꼭 필요한 실전 기술입니다.
LangGraph로 AI가 스스로 판단하는 에이전틱 AI 에이전트를 만듭니다. 검색 결과가 부족하면 질문을 자동으로 바꿔서 다시 검색하고, 관련 없는 문서는 걸러냅니다. 마지막으로 텔레그램 봇을 연결해서 스마트폰에서도 사용할 수 있게 완성합니다.
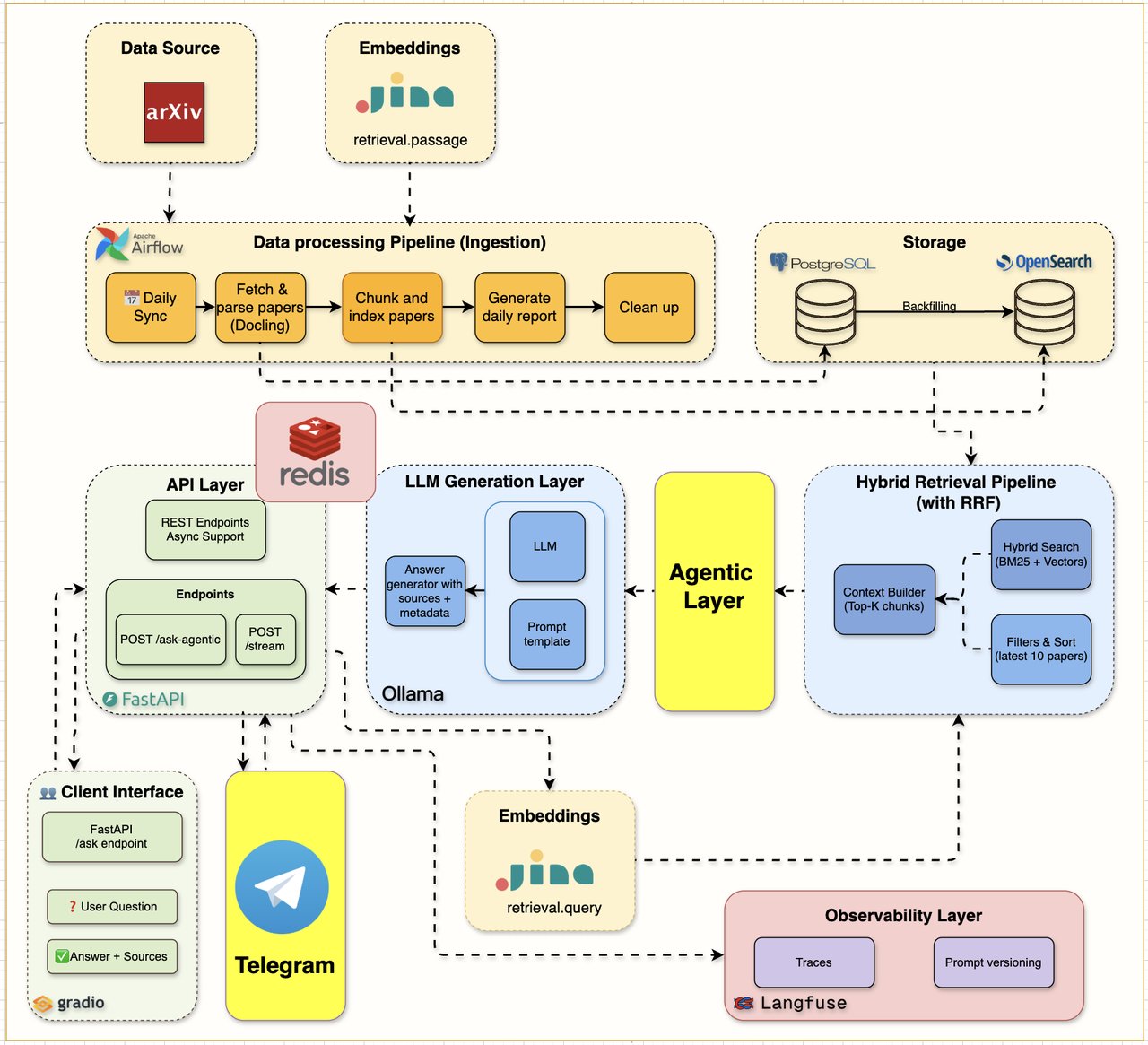
사용하는 무료 AI 도구 총정리
이 강좌의 가장 큰 장점은 유료 API가 하나도 필요 없다는 것입니다.
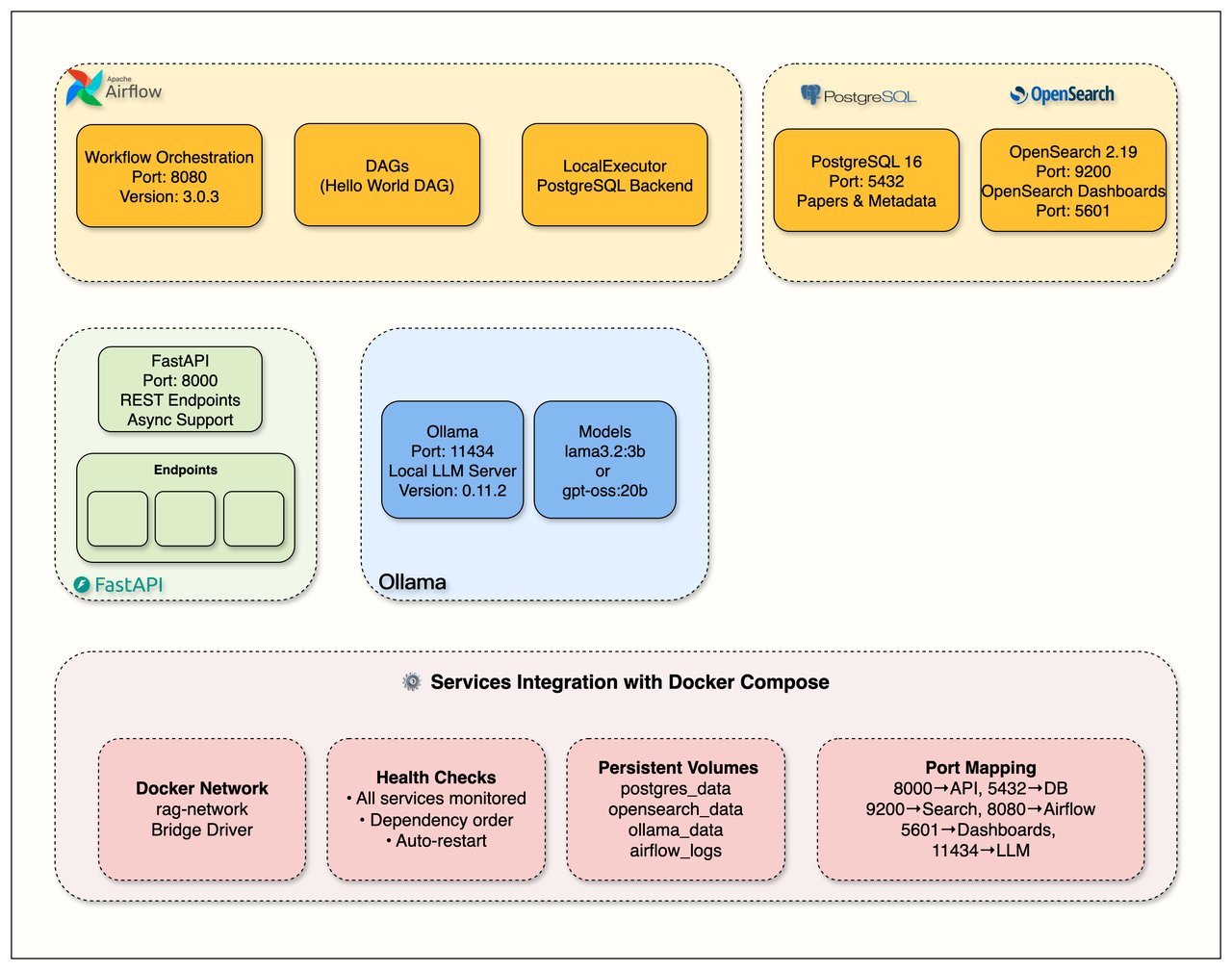
로컬 RAG 시스템 설치 및 시작 방법
필요한 것: Docker Desktop, Python 3.12 이상, RAM 8GB 이상, 디스크 20GB 이상
# 저장소 복제
git clone https://github.com/jamwithai/production-agentic-rag-course.git
cd arxiv-paper-curator
# 환경 설정
cp .env.example .env
# 의존성 설치 (uv 패키지 매니저 사용)
uv sync
# 모든 서비스 한 번에 실행
docker compose up --build -d
# 정상 작동 확인
curl http://localhost:8000/health각 주차별로 별도 브랜치(week1.0, week2.0 ... week7.0)가 있어서 원하는 주차부터 시작할 수도 있습니다. 매 주차마다 Jupyter 노트북과 블로그 포스트가 함께 제공됩니다.
이 강좌만의 차별점 — 실무형 RAG 튜토리얼
인터넷에 RAG 튜토리얼은 넘쳐나지만, 대부분은 "OpenAI API 키 넣고 → LangChain 3줄 → 끝" 수준입니다. 실제 회사에서 쓸 수 있는 시스템과는 거리가 멉니다.
이 강좌는 다릅니다.
- 기초부터 쌓는다 — AI 임베딩을 붙이기 전에 키워드 검색부터 완성합니다. 실제 기업이 RAG를 구축하는 순서와 같습니다.
- 운영 환경을 고려한다 — 캐싱, 모니터링, 에러 처리, 재시도 로직까지 포함합니다. 데모용이 아니라 실무용입니다.
- 외부 API 의존 제로 — Ollama로 로컬 AI를 쓰기 때문에 API 비용도, 데이터 유출 걱정도 없습니다.
- 모바일까지 확장 — 7주차에 텔레그램 봇을 연결해서 스마트폰에서도 질문할 수 있게 만듭니다.
로컬 AI 구축 시 주의할 점
현재 깃허브 이슈를 보면, 초기 세팅 과정에서 Airflow 로그인 정보를 찾기 어렵거나 서비스 헬스체크가 실패하는 사례가 보고되고 있습니다. Docker와 터미널에 익숙하지 않은 분이라면 1주차에서 시간이 좀 걸릴 수 있습니다. 다만, 각 주차별 Jupyter 노트북이 상세하게 안내하고 있어 차근히 따라가면 충분히 완성할 수 있습니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기