Meta AI 번역 1,600개 언어 지원 — 8B 소형 모델이 70B를 이긴 이유
Meta Omnilingual MT가 1,600개 언어 AI 번역에 성공했습니다. 80억 파라미터 소형 모델이 700억 대형 모델보다 번역 품질이 높았던 비결, 소멸 위기 언어 지원 현황, 데모 링크까지 한눈에 정리합니다.
• ChatGPT는 소설 3권이 한계인데 이 AI는 1,000권을 기억합니다 — EverMind MSA
• 이름을 숨기고 AI 사용량 1위를 찍은 모델의 정체는 스마트폰 회사 Xiaomi였습니다
• 내 맥북이 AI 보안 카메라가 됐다 — 월 구독료 0원에 정확도 93.8%, 오픈소스 SharpAI
Meta가 세계 최초로 1,600개 언어를 번역하는 AI 모델 Omnilingual MT를 발표했습니다. 구글 번역(Google Translate)이 133개, 기존 AI 번역 시스템이 최대 200개 언어를 지원하던 것과 비교하면 압도적인 확장입니다. 더 놀라운 건 80억 파라미터(8B) 소형 모델이 700억(70B) 대형 모델보다 번역 품질이 높았다는 실험 결과입니다. AI 번역 기술의 패러다임이 '크기'에서 '전문화'로 바뀌고 있습니다.
• 지원 언어: 기존 200개 → 1,600개 (8배 증가)
• 400개 이상 언어에서 핵심 의미를 정확히 전달
• 80억 파라미터 모델이 700억 파라미터 모델을 능가 — 전문화가 크기를 이겼습니다
• 소멸 위기 언어, 디지털 자원이 거의 없는 언어까지 포함
• 새로운 평가 도구와 데이터셋 함께 공개
AI 번역 지원 언어 200개에서 1,600개로 — 8배 확장의 의미
Meta AI 연구팀 29명이 3월 17일 arXiv에 발표한 논문에 따르면, Omnilingual MT(OMT)는 세계 최초로 1,600개 이상의 언어를 지원하는 기계 번역 시스템입니다.
기존의 대표적 AI 번역 시스템이었던 NLLB(No Language Left Behind)는 약 200개 언어를 지원했습니다. OMT는 이를 8배로 확장했습니다. 구글 번역의 133개 언어와 비교하면 약 12배에 달하는 규모입니다.
다만, 1,600개 언어 모두에서 완벽한 번역을 제공하는 것은 아닙니다. 연구팀은 성능을 세 단계로 구분했습니다.
2단계 — 약 1,200개 언어: '의미 있는 수준'의 번역 생성 가능
3단계 — 약 400개 언어: 문장의 핵심 의미를 정확히 전달 (이전 시스템 대비 2배)
연구팀은 "기존 모델도 다양한 언어를 '이해'할 수는 있지만, 그 언어로 '생성'하는 것은 완전히 다른 문제"라고 설명했습니다. AI가 캄보디아어를 읽고 뜻을 파악할 수는 있어도, 캄보디아어로 자연스러운 문장을 만들어내는 것은 훨씬 어렵다는 뜻입니다. OMT는 바로 이 '생성의 병목'을 해결하는 데 집중했습니다.
소형 AI 모델이 대형 모델을 이긴 번역 품질 실험
이번 연구에서 가장 주목할 만한 발견은 모델 크기와 번역 품질의 관계입니다.
일반적으로 AI 모델은 클수록 성능이 좋다고 알려져 있습니다. 그런데 번역에서는 달랐습니다. OMT의 10억~80억 파라미터(AI의 '두뇌 크기'를 나타내는 단위) 모델이 700억 파라미터 범용 모델의 번역 성능을 넘어섰습니다.
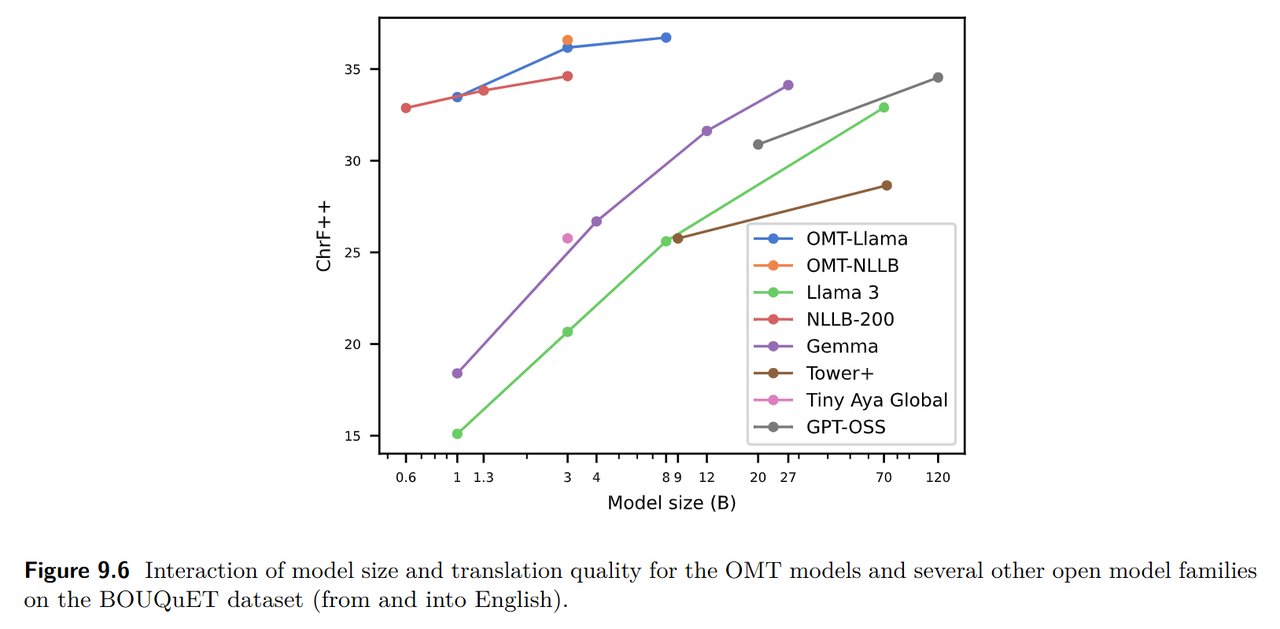
▲ 모델 크기(가로축)와 번역 품질(세로축) 관계. 파란색(OMT-LLaMA)과 주황색(OMT-NLLB)이 훨씬 큰 모델들(회색 GPT-OSS 120B, 녹색 Llama 3 70B)보다 높은 점수를 기록했습니다. 출처: arXiv 논문 Figure 9.6
위 차트에서 볼 수 있듯이, 번역 전문으로 훈련된 작은 모델(OMT-LLaMA 8B, 파란색)이 범용 대형 모델(GPT-OSS 120B, 회색)보다 번역 품질이 높습니다. '작지만 전문화된 AI'가 '크지만 범용적인 AI'를 이긴 셈입니다.
이것은 실용적으로도 큰 의미가 있습니다. 작은 모델은 비용이 적게 들고, 빠르며, 일반 컴퓨터에서도 돌릴 수 있습니다. 1,600개 언어 번역 서비스가 대규모 서버 없이도 가능해질 수 있다는 뜻입니다. AI 자동화 시대에 번역 비용을 획기적으로 낮출 수 있는 가능성을 열어준 결과입니다.
OMT-LLaMA vs OMT-NLLB — 두 가지 기계 번역 방식 비교
OMT는 두 가지 방식의 번역 모델을 실험했습니다.
Meta의 LLaMA 3 모델(ChatGPT처럼 대화하는 AI)을 번역 전문가로 훈련시킨 것입니다. 1B, 3B, 8B 세 가지 크기로 제공됩니다. 번역할 때 비슷한 문장 예시를 참고하는 '검색 증강 번역(번역할 문장과 비슷한 과거 번역 사례를 자동으로 찾아 참고하는 기술)' 기능이 포함되어 있습니다.
기존 NLLB 번역 시스템의 구조를 개선한 것입니다. '인코더-디코더'(입력을 이해하는 부분과 번역을 생성하는 부분이 나뉜 구조) 방식으로, 특히 번역 데이터가 부족한 언어에서 강점을 보입니다.
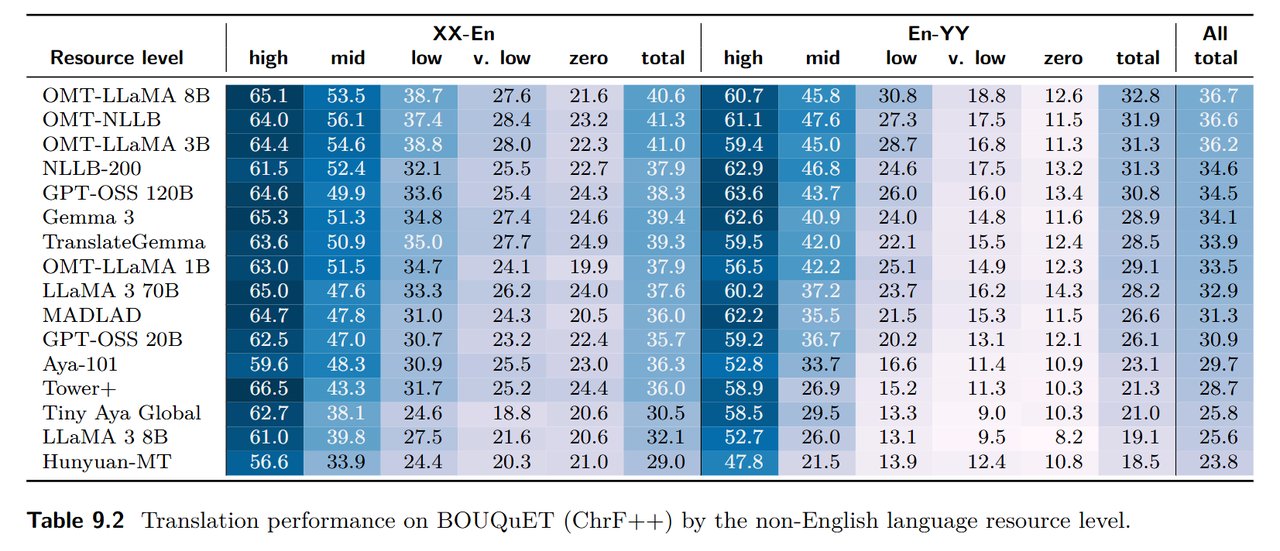
▲ 다양한 모델 크기에서의 번역 성능 비교. OMT 모델들이 기존 모델 대비 일관되게 높은 점수를 기록합니다. 출처: arXiv 2603.16309
1,600개 언어 학습 데이터 확보 — 합성 역번역과 어휘 확장 기술
AI 번역 모델을 훈련시키려면 '이 문장은 A 언어로 이렇게, B 언어로 이렇게 번역된다'는 병렬 데이터가 필요합니다. 영어-프랑스어처럼 자료가 풍부한 언어는 문제가 없지만, 세계 대부분의 언어는 이런 데이터가 거의 없습니다.
연구팀은 이 문제를 여러 방법으로 해결했습니다.
합성 역번역: AI가 먼저 번역하고, 그 결과를 다시 역방향으로 번역해서 학습 데이터를 자동 생성하는 방법. 자연 데이터에 5~10% 비율로 섞으면 최적 성능
어휘 확장: LLaMA 3의 기본 어휘(12만 8천 개)를 25만 6천 개로 2배 확대해서 비라틴 문자 언어의 처리 효율을 높임
합성 데이터가 AI 번역에 중요한 이유
전 세계 7,000여 개 언어 중 대다수는 디지털 텍스트 자체가 부족합니다. 합성 역번역은 이 데이터 부족 문제를 우회하는 핵심 기술입니다. 연구팀은 합성 데이터의 비율을 5~10%로 유지했을 때 번역 품질이 가장 높았다고 밝혔습니다. 비율이 너무 높으면 오히려 오류가 증폭되는 '환각(hallucination)' 현상이 나타났습니다. 이 균형점을 찾아낸 것이 OMT의 기술적 기여 중 하나입니다.
해커뉴스 커뮤니티 반응 — 기대와 우려가 공존
해커뉴스 토론에서는 기대와 비판이 함께 나왔습니다.
캄보디아 출신 사용자는 "Meta의 번역은 다른 서비스에 비해 상당히 부족하다"며, 특히 크메르어 같은 소수 언어에서 맥락 이해가 떨어진다고 지적했습니다. 또 다른 사용자는 "중국어조차 제대로 번역하지 못한다"고 말했습니다.
언어 수에 대한 의문도 있었습니다. "1,600개는 많지만, 세계 언어가 4,000~8,000개인 점을 고려하면 '옴니(전부)'라는 이름은 과장"이라는 의견도 나왔습니다.
다만, 연구팀 자체도 한계를 인정하고 있습니다. 논문에서 "우리는 긴 꼬리 언어들의 기계 번역을 '완전히 해결'하기에는 아직 멀었다"고 명시했고, 사람이 직접 평가한 언어 쌍은 57개에 그쳤습니다.
소멸 위기 언어 보존과 AI 번역의 미래
유네스코에 따르면 세계 언어의 약 40%가 소멸 위기에 처해 있습니다. 이 언어들은 디지털 자료가 거의 없어서 AI 번역 시스템의 혜택을 받지 못했습니다.
OMT가 이런 언어까지 지원하기 시작했다는 것은 의미 있는 첫 걸음입니다. 아직 완벽한 번역과는 거리가 있지만, 기존 시스템에서는 아예 불가능했던 언어들에 대한 번역이 '시도'라도 가능해졌다는 점이 중요합니다.
연구팀은 OMT가 단순 번역을 넘어 대화, 추론, 멀티모달(텍스트·음성·이미지를 함께 처리하는) 활용으로 확장될 수 있다고 전망했습니다. Meta가 이미 발표한 Omnilingual ASR(음성 인식)과 결합하면, 소수 언어 화자가 말한 것을 AI가 듣고 다른 언어로 번역하는 것도 가능해집니다.
이처럼 에이전틱 AI의 발전은 번역뿐 아니라 다양한 분야에서 전문화된 소형 모델의 가능성을 열어가고 있습니다. 프롬프트 엔지니어링을 활용하면 이런 번역 모델의 출력 품질을 더욱 높일 수도 있습니다.
Omnilingual MT 직접 체험하기 — 데모와 논문 링크
Meta는 Omnilingual 프로젝트의 인터랙티브 언어 지구본 데모를 공개했습니다. 지원되는 1,600개 이상의 언어를 지구본 위에서 탐색할 수 있습니다.
다만, 모델 가중치(AI를 실행하는 데 필요한 파일)의 공개 다운로드는 아직 확인되지 않았습니다. 논문과 평가 데이터셋(BOUQuET, Met-BOUQuET)은 공개되어 있어 연구자들이 활용할 수 있습니다.
정리하면
Meta Omnilingual MT는 AI 번역의 범위를 200개에서 1,600개 언어로 확장한 첫 번째 시스템입니다. 완벽한 번역과는 거리가 있지만, 그동안 어떤 AI 번역기도 다루지 못했던 수백 개의 소수 언어에 대한 번역이 시작됐다는 점에서 의미가 큽니다.
특히 '크기가 아니라 전문화가 답'이라는 실험 결과는, 앞으로 더 작고 효율적인 AI 모델이 다양한 분야에서 대형 모델을 대체할 수 있다는 가능성을 보여줍니다. AI 자동화와 API 연동이 확산되면서, 이런 전문화된 소형 모델의 활용 범위는 더욱 넓어질 전망입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기
출처