AI 메모리 1억 토큰 시대 — 소설 1,000권 기억하는 EverMind MSA 기술 분석
GPU 2장으로 소설 1,000권(1억 토큰)을 기억하는 AI가 가능해졌습니다. EverMind MSA는 RAG 대비 정확도 16% 향상, MIT 오픈소스 공개 예정. 롱컨텍스트 기술의 원리와 실전 활용 가능성을 분석합니다.
• 이름을 숨기고 AI 사용량 1위를 찍은 모델의 정체는 스마트폰 회사 Xiaomi였습니다
• 내 맥북이 AI 보안 카메라가 됐다 — 월 구독료 0원에 정확도 93.8%, 오픈소스 SharpAI
• AI 코딩 도구에 2400만 원 쓴 개발자가 결국 직접 만들었습니다 — OmO 스타 4만 2천
ChatGPT나 Claude 같은 LLM에게 긴 문서를 읽히다 보면 앞부분을 까먹는 경험, 해보셨을 겁니다. 현재 AI 메모리(컨텍스트 윈도우)의 한계는 소설 약 3권 분량(100만 토큰)입니다. 그런데 이 롱컨텍스트(Long Context) 한계를 100배 뛰어넘는 기술이 나왔습니다.
미국 샌머테이오 소재 AI 스타트업 EverMind가 3월 19일 공개한 MSA(Memory Sparse Attention)는 AI가 한 번에 1억 토큰 — 소설로 따지면 약 1,000권 — 을 기억하면서도 정확도가 9% 미만으로만 떨어지는 기술입니다.
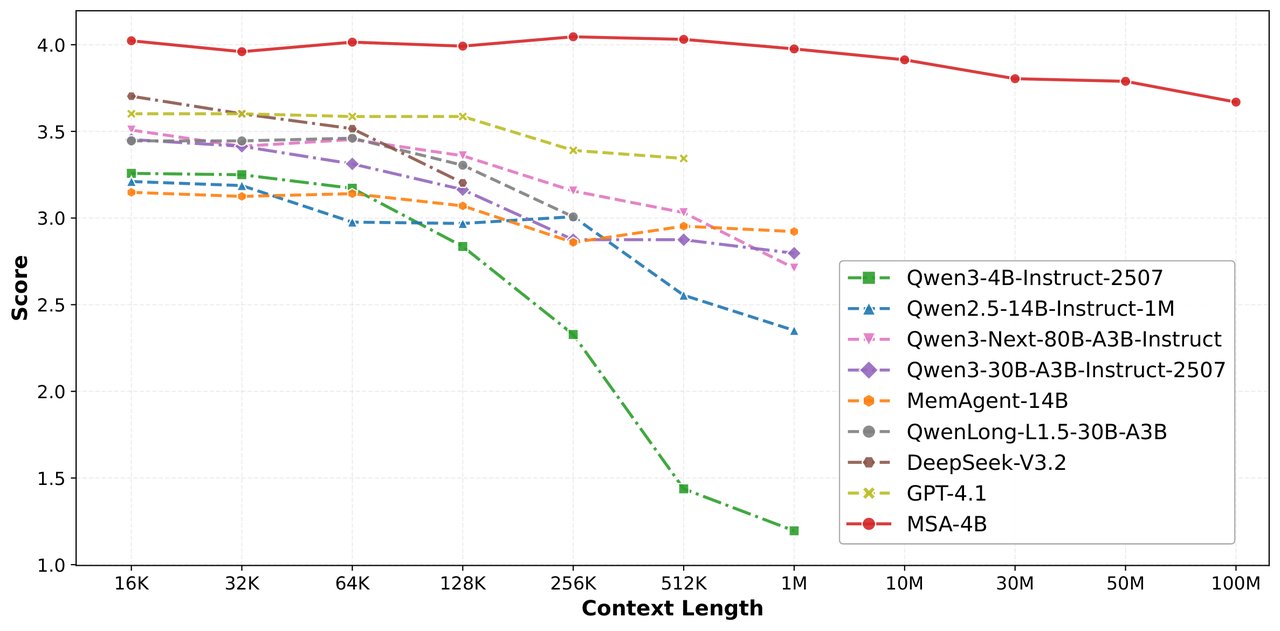
위 그래프가 핵심을 보여줍니다. 빨간 선(MSA)이 1억 토큰까지 거의 수평을 유지하는 동안, GPT-4.1, DeepSeek, Qwen 같은 기존 모델들은 100만 토큰 부근에서 성능이 절반 이하로 추락합니다.
AI 컨텍스트 윈도우란 — LLM 기억력이 중요한 이유
AI의 '기억력'은 컨텍스트 윈도우(Context Window, 한 번에 처리할 수 있는 텍스트 양)라고 부릅니다. 이게 클수록 AI는 더 많은 자료를 한꺼번에 읽고 참고할 수 있습니다.
쉽게 비유하면 — 지금까지의 AI는 시험 볼 때 교과서 3권만 펼쳐놓을 수 있었습니다. MSA는 교과서 1,000권을 동시에 펼쳐놓고 필요한 부분만 빠르게 찾아보는 기술입니다.
실제 활용 예시를 들면:
• 법률 사무소: 수천 건의 판례를 한꺼번에 읽고 관련 조항을 찾아준다
• 의료: 환자의 10년치 진료 기록 전체를 참고해서 진단을 돕는다
• 연구: 논문 수백 편을 동시에 분석해서 새로운 연결고리를 발견한다
• 기업: 회사의 모든 문서·이메일·회의록을 기억하는 에이전틱 AI 비서가 가능해진다
MSA vs RAG — 기존 AI 메모리 방식과 정확도 비교
AI의 기억력을 늘리려는 시도는 이전에도 있었습니다. 가장 많이 쓰이는 방법은 RAG(검색 증강 생성, Retrieval-Augmented Generation) — AI가 필요할 때 외부 데이터베이스에서 정보를 '검색'해오는 방식입니다. 마치 시험 중에 교과서를 찾아보는 것과 비슷합니다.
하지만 RAG는 검색이 정확하지 않으면 엉뚱한 정보를 가져오는 문제가 있습니다. MSA는 이 방식과 근본적으로 다릅니다.
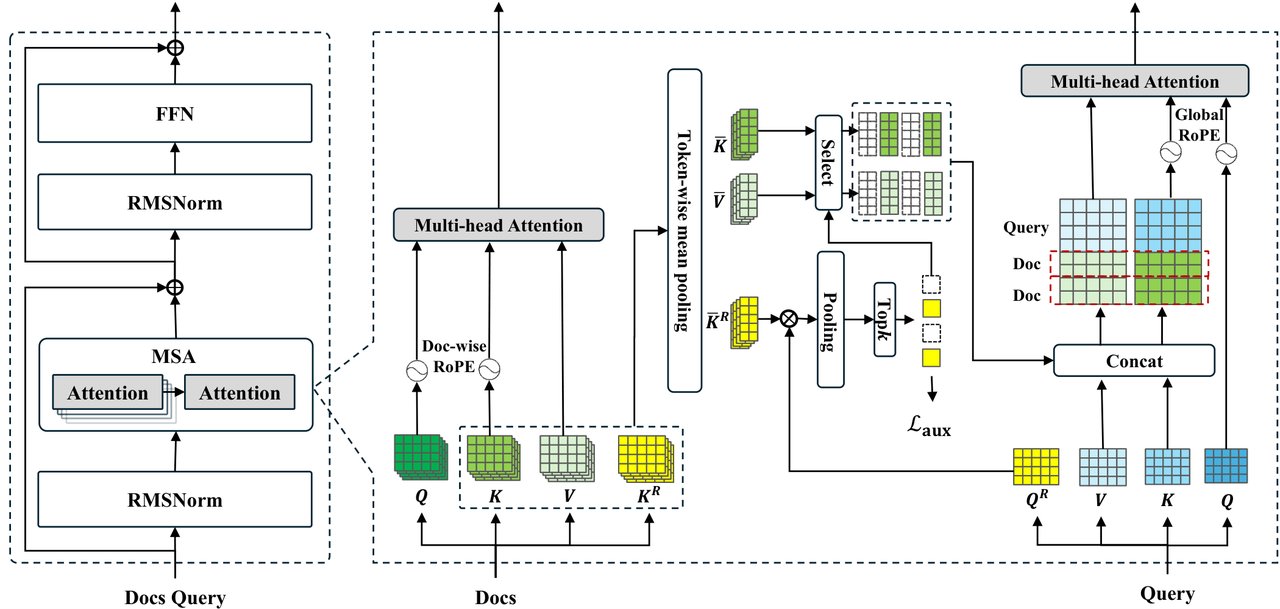
MSA의 핵심 원리를 쉽게 설명하면 이렇습니다:
1단계. 모든 문서를 미리 읽고 '요약 색인'을 만들어둡니다 (오프라인)
2단계. 질문이 들어오면, 관련 있는 문서만 빠르게 골라냅니다 (라우팅)
3단계. 골라낸 문서의 원본 내용만 꺼내서 답변을 만듭니다 (생성)
9개 벤치마크 테스트에서 MSA는 기존 RAG 방식보다 16.0%, RAG에 재정렬 기법을 더한 것보다 11.5%, 최신 기법인 HippoRAG2보다 14.8% 높은 점수를 기록했습니다. 특히 4B(40억) 파라미터 크기의 작은 모델로 235B(2,350억) 파라미터 급 대형 모델을 이긴 데이터셋도 여럿 있습니다.
GPU 2장으로 1억 토큰 처리 — MSA의 메모리 효율
1억 토큰을 처리하려면 엄청난 컴퓨팅 자원이 필요할 것 같지만, MSA는 A800 GPU 2장이면 충분합니다. 비결은 '메모리 분산 저장' 방식입니다:
• 라우팅 키(어떤 문서가 관련 있는지 판단하는 색인) → GPU 메모리에 상주
• 실제 내용(문서 원본) → CPU 메모리에 저장, 필요할 때만 GPU로 전송
이 방식으로 169GB에 달하는 데이터를 효율적으로 관리합니다. 기존 방식대로라면 GPU 수십 장이 필요한 작업입니다.
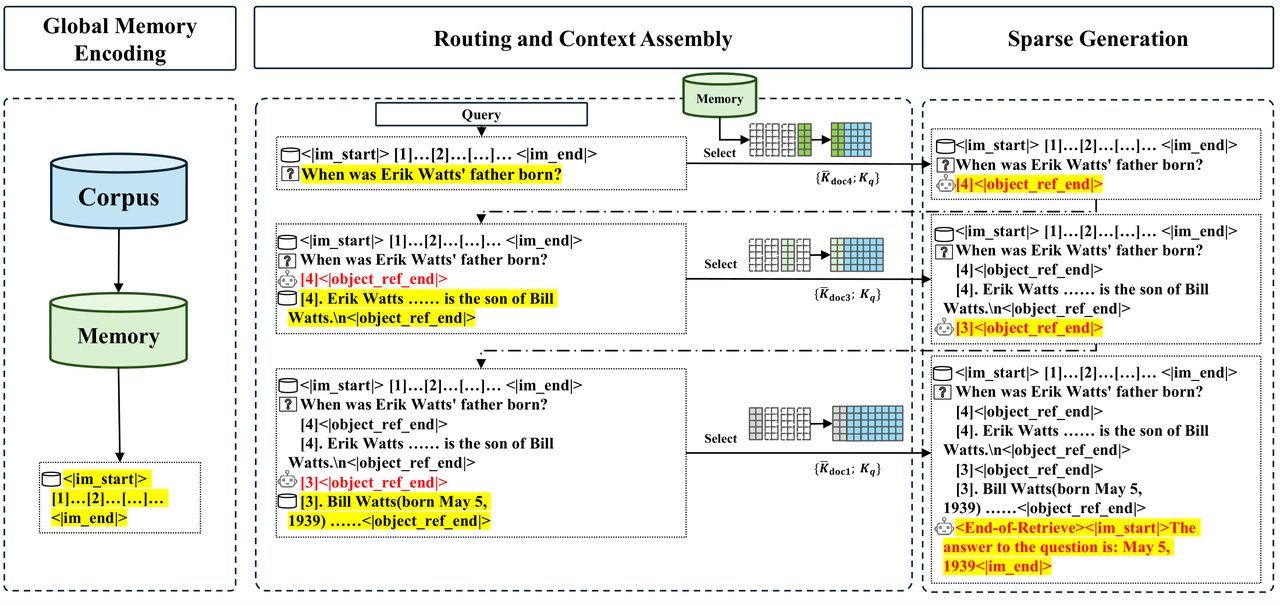
NIAH 테스트 — 1억 토큰 속 바늘 찾기 정확도
AI 기억력 테스트 중 가장 유명한 것이 NIAH(Needle In A Haystack) — 거대한 텍스트 더미 속에 숨겨진 특정 정보를 찾아내는 테스트입니다.
MSA는 100만 토큰 규모에서 94.84% 정확도를 기록했습니다. 같은 크기의 기본 모델이 24.69%로 무너지는 것과 비교하면 압도적인 차이입니다. 32K에서 1M 토큰까지 겨우 3.93%포인트만 떨어졌습니다.
EverMind MSA 오픈소스 공개 — 사용 가능 시점
아직은 아닙니다. 현재 GitHub에 논문과 프로젝트 페이지가 공개되어 있고, 코드와 모델은 'Coming Soon' 상태입니다. MIT 라이선스로 공개될 예정이므로 누구나 무료로 사용할 수 있게 됩니다.
EverMind는 중국 게임·투자 그룹 Shanda Group 산하 AI 회사로, '발견적 AI(Discoverative AI)' — AI가 단순히 글을 쓰는 것을 넘어 새로운 지식을 발견하는 것 — 을 목표로 하고 있습니다.
AI 롱컨텍스트 시대 — 실전에서 무엇이 달라지나
MSA의 핵심 의미는 AI의 기억력이 더 이상 병목이 아니게 된다는 것입니다. 지금까지는 AI에게 '한 번에 얼마나 많이 읽힐 수 있느냐'가 큰 제약이었습니다. 이 제약이 풀리면:
• AI 챗봇이 수개월간의 대화를 전부 기억하고 맥락을 유지할 수 있습니다
• 기업용 AI가 회사의 전체 지식 베이스를 실시간으로 참조하는 에이전트 팀을 구성할 수 있습니다
• 개인 AI 비서가 내 이메일·문서·메모를 통째로 '기억'할 수 있습니다
이런 AI를 직접 활용하는 방법이 궁금하다면, AI API 연동 가이드에서 실전 사용법을 확인해 보세요.
EverMind는 이 기술의 궁극적 비전을 이렇게 설명합니다: "메모리가 독립적이고 교체 가능한 서비스가 되면, 사용자의 데이터와 '기억 자산'은 더 이상 특정 모델이나 회사에 종속되지 않는다."
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기