수학 0.4→0.9, 코딩 버그 수정 2배 — NVIDIA ProRL Agent GPU 훈련 인프라 오픈소스
NVIDIA AI 연구팀이 멀티턴 AI 에이전트 강화학습 훈련 인프라 'ProRL Agent'를 오픈소스로 공개했습니다. 소프트웨어 버그 수정 성공률 2배, 수학 정답률 125%, STEM 에이전트 성능 225% 향상을 32개 H100 GPU로 달성했습니다.
2026년 3월, NVIDIA를 포함한 13명의 공동 연구자들이 AI 에이전트 훈련 분야에서 주목할 만한 성과를 발표했습니다. 이름하여 ProRL Agent입니다. AI가 복잡한 소프트웨어 버그를 수정하거나 고난도 수학 문제를 푸는 능력이 기존 방식보다 최대 2배 이상 향상되었으며, 연구에 사용된 전체 코드와 방법론이 CC BY 4.0 라이선스로 무료 공개되어 누구나 활용할 수 있게 되었습니다.

기존 AI 훈련 방식의 병목 — 왜 새로운 인프라가 필요했나
AI 에이전트를 강화학습(RL)으로 훈련할 때는 두 가지 핵심 과정이 필요합니다. 첫째는 롤아웃(Rollout) — AI가 실제로 환경과 상호작용하며 행동을 수행하는 단계이고, 둘째는 RL 학습 루프 — 그 결과를 바탕으로 AI 모델의 가중치를 업데이트하는 단계입니다.
기존의 주요 AI 훈련 프레임워크들, 예를 들어 SkyRL, VeRL-Tool, Agent Lightning 등은 이 두 과정이 하나의 코드베이스에 단단히 결합(Tightly Coupled)되어 있었습니다. 이 구조에는 다음과 같은 심각한 문제점이 있었습니다.
- 유연성 부족: 롤아웃 환경을 바꾸려면 학습 루프 전체를 함께 수정해야 했습니다. 소프트웨어 엔지니어링·수학·코딩 등 도메인마다 다른 환경이 필요한데, 기존 방식에서는 이 전환이 매우 어려웠습니다.
- GPU(그래픽카드처럼 생긴 AI 연산 전용 하드웨어) 낭비: 롤아웃 실행 중에는 모델 가중치 업데이트가 불가능하고, 업데이트 중에는 롤아웃이 멈춥니다. 즉, 둘 중 하나가 유휴 상태로 GPU 자원을 낭비하게 됩니다.
- 확장 어려움: HPC(대학/연구소에서 쓰는 초고성능 컴퓨터 클러스터) 환경에서 수십~수백 개의 GPU로 분산 훈련을 확장할 때, 결합된 구조는 관리와 디버깅이 매우 복잡해집니다.
- 마이그레이션 비용: 새로운 도메인에 적용하거나 모델을 교체하려면 전체 훈련 파이프라인을 다시 설계해야 하는 경우가 많았습니다.
NVIDIA 연구팀은 이 문제를 근본적으로 해결하기 위해 롤아웃과 학습 루프를 완전히 분리하는 새로운 아키텍처를 설계했습니다.
ProRL의 핵심 혁신 — Rollout-as-a-Service 아키텍처
ProRL Agent의 핵심 아이디어는 Rollout-as-a-Service(서비스형 롤아웃)입니다. 롤아웃 생성 과정을 독립적인 HTTP API 서비스로 분리하여, RL 학습 루프가 이 API를 호출하는 방식으로 동작합니다. 마치 웹 서비스에서 결제 시스템을 별도 API로 분리해 관리하듯, AI 훈련의 두 핵심 과정을 독립 모듈로 만든 것입니다.
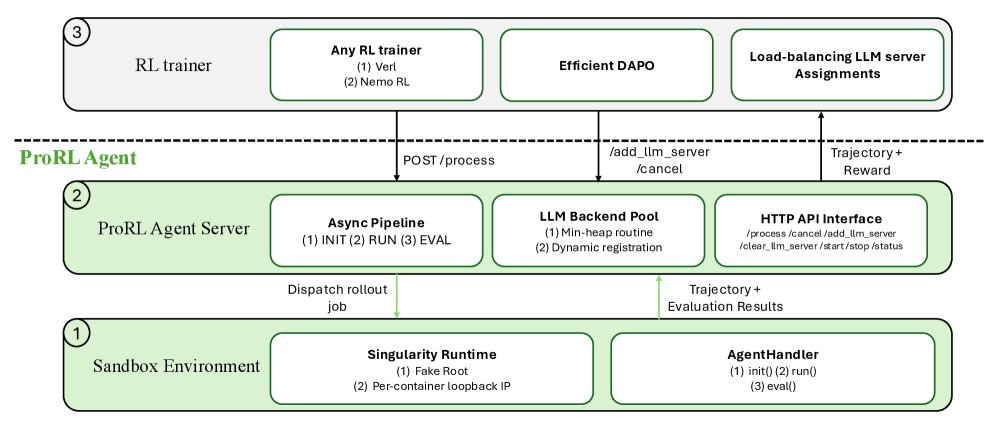
ProRL은 훈련 과정을 3단계 비동기 파이프라인으로 구성합니다.
각 훈련 인스턴스에 필요한 환경을 독립적으로 세팅합니다. 소프트웨어 버그 수정 작업이라면 해당 코드 저장소를 준비하는 단계입니다.
AI 에이전트가 실제 환경과 상호작용하며 멀티턴 대화를 수행합니다. vLLM(AI 모델을 빠르게 실행해주는 추론 서버)을 통해 AI 모델의 응답을 생성합니다.
에이전트의 행동 결과를 평가하여 보상 신호를 생성합니다. 이 신호가 RL 학습 루프로 전달되어 모델을 업데이트합니다.
이 세 단계는 각각 독립적인 워커 풀(Worker Pool)에서 병렬로 처리됩니다. 한 인스턴스가 EVAL 단계에 있는 동안 다른 인스턴스는 RUN 단계를, 또 다른 인스턴스는 INIT 단계를 동시에 진행할 수 있습니다. 이를 통해 GPU 유휴 시간을 크게 줄일 수 있었습니다.
또한 로드 밸런싱(부하 분산) 기능을 적용하여 초당 0.37개 인스턴스의 처리량을 달성했으며, 스테일(오래된) 작업을 자동으로 정리하는 메커니즘으로 GPU 활용률 78%를 달성했습니다. 이는 기존 결합형 방식 대비 상당한 개선입니다.
특히 Singularity(보안이 엄격한 연구 환경에서 쓰는 격리 실행 컨테이너)를 활용한 rootless HPC 지원 덕분에, 보안 정책이 엄격한 대학이나 국가 연구소의 슈퍼컴퓨터 환경에서도 관리자 권한 없이 실행할 수 있습니다. 이는 학술 연구자들이 ProRL을 도입하는 데 있어 큰 장벽을 제거합니다.
4개 도메인에서 검증된 성능 — 수치로 보는 ProRL의 효과
NVIDIA 연구팀은 ProRL Agent를 소프트웨어 엔지니어링, 수학, STEM, 코딩 4개 도메인에서 검증했습니다. 기준선은 기존 SkyRL-v0 방식입니다.
14B 모델: 15.4% → 23.6%
SWE-Bench(AI가 실제 소프트웨어 버그를 얼마나 잘 고치는지 측정하는 벤치마크)는 실제 오픈소스 프로젝트의 버그 티켓을 AI에게 주고, AI가 코드를 수정하여 테스트를 통과시킬 수 있는지 평가하는 업계 표준 벤치마크입니다. 14B(140억 파라미터) 모델이 23.6%를 기록했다는 것은, 실제 소프트웨어 개발 보조 도구로 활용 가능한 수준에 근접했다는 의미입니다.
이 모든 성능 향상은 단 32개 NVIDIA H100 GPU 환경에서, 배치 크기 32, 인스턴스당 8회 롤아웃, 293개 SWE-GYM 예제로 약 66스텝 학습한 결과입니다. 수천 개의 GPU와 방대한 데이터가 필요할 것 같지만, 놀랍도록 효율적인 설정으로 달성되었습니다.
직접 시작하기 — ProRL Agent 설치 및 사용 방법
ProRL Agent 서버는 GitHub에 오픈소스로 공개되어 있으며, NVIDIA NeMo Gym(GitHub 스타 784개)과 통합되어 있습니다. 아래는 기본적인 설치 및 서버 실행 방법입니다.
# 1. ProRL Agent Server 저장소 클론
git clone https://github.com/NVIDIA-NeMo/ProRL-Agent-Server.git
cd ProRL-Agent-Server
# 2. 의존성 설치 (Python 환경 기준)
pip install -e .
# 3. ProRL Agent 서버 실행 (HTTP API 서버 시작)
python -m prorl_agent.server --host 0.0.0.0 --port 8080
# 4. NVIDIA NeMo Gym과 함께 SWE-Bench 훈련 실행 예시
# NeMo Gym 저장소: https://github.com/NVIDIA-NeMo/Gym
git clone https://github.com/NVIDIA-NeMo/Gym.git
cd Gym
python train.py --domain swe --agent-server http://localhost:8080 --gpus 32HPC 환경(Singularity) 사용자를 위한 팁: ProRL Agent는 rootless Singularity(보안이 엄격한 연구 환경에서 쓰는 격리 실행 컨테이너) 컨테이너를 기본 지원합니다. 관리자 권한(sudo) 없이도 대학/국가 슈퍼컴퓨터에서 실행 가능하며, 컨테이너 이미지는 프로젝트 GitHub 페이지에서 제공됩니다.
앞으로의 전망 — ProRL이 바꿀 AI 개발의 미래
ProRL Agent의 오픈소스 공개는 단순한 논문 발표를 넘어, AI 에이전트 훈련 생태계 전반에 영향을 줄 것으로 보입니다. 몇 가지 중요한 시사점을 살펴보겠습니다.
1. 소규모 연구팀도 수준 높은 AI 에이전트 훈련 가능
기존에는 대규모 GPU 클러스터와 복잡한 인프라 설정이 필요해 일부 빅테크 기업만이 고성능 AI 에이전트 훈련이 가능했습니다. ProRL의 효율적인 아키텍처는 32개 GPU(H100 기준)만으로도 의미 있는 성능 향상을 달성할 수 있음을 보여주었습니다. 이는 중소 기업이나 대학 연구팀에도 문턱을 낮춰주는 것입니다.
2. 도메인 확장의 유연성
Rollout-as-a-Service 구조 덕분에, 새로운 도메인(예: 법률 문서 분석, 의료 진단 보조 등)에 AI 에이전트를 적용할 때 전체 훈련 파이프라인을 다시 설계할 필요가 없습니다. HTTP API 서버만 해당 도메인에 맞게 구현하면 됩니다.
3. 오픈소스 생태계 활성화
NVIDIA NeMo Gym(GitHub 스타 784개)과의 통합을 통해, 이미 검증된 소프트웨어 엔지니어링·수학·STEM·코딩 환경을 즉시 활용할 수 있습니다. ProRL Agent Server 자체도 빠르게 커뮤니티의 관심을 받고 있습니다(GitHub 스타 68개, 공개 초기 기준).
4. 산업별 AI 에이전트 고도화 가속
SWE-Bench Verified에서 14B 모델이 23.6%를 기록한 것은, 실제 기업 소프트웨어 개발 환경에서 AI가 버그를 자동으로 수정하는 시대가 가까워지고 있음을 의미합니다. 비슷한 방식으로 훈련된 에이전트가 의료, 법률, 금융 등 전문 도메인에 확산될 것으로 예상됩니다.
물론 현재의 23.6%라는 수치가 인간 개발자를 완전히 대체하기에는 아직 부족합니다. 하지만 ProRL이 보여준 방향성 — 인프라의 유연성, GPU 효율성, 오픈소스 공개 — 은 AI 에이전트 연구 속도를 전반적으로 높일 것으로 기대됩니다. 13명의 NVIDIA 연구자들이 증명한 이 방법론이 앞으로 어떤 후속 연구를 이끌어낼지 주목할 필요가 있습니다.