159GB짜리 AI를 40GB로 줄여도 정확도는 90% — 브라우저에서 직접 보는 양자화 원리
80B 파라미터 AI를 159GB 그대로 쓰면 일반 PC 불가능. 양자화로 40GB까지 줄이면 정확도 90% 유지, 속도는 오히려 빨라집니다. ngrok 엔지니어가 브라우저에서 직접 조작하는 인터랙티브 시각화로 공개.

내 컴퓨터에서 AI를 못 돌리는 진짜 이유 — 159GB RAM
최근 AI 모델의 성능은 눈부시게 발전했지만, 정작 일반 사용자가 자신의 컴퓨터에서 최신 AI를 돌리기란 여전히 쉽지 않습니다. 그 핵심 원인은 바로 모델의 크기입니다.
예를 들어 800억(80B) 개의 파라미터(parameter, AI 모델이 학습을 통해 얻은 수치 값)를 가진 Qwen-3-Coder-Next 같은 모델을 원본 그대로 실행하려면 무려 159.4GB의 RAM이 필요합니다. 일반 소비자용 PC의 RAM은 16~64GB 수준이니, 이런 모델은 사실상 개인이 돌리는 것이 불가능합니다. 클라우드 서버나 전문 연구 장비를 갖춰야만 실행할 수 있었죠.
그렇다면 이 거대한 모델을 일반 PC에서 돌릴 방법은 없을까요? 바로 여기서 양자화(Quantization)가 등장합니다. 양자화를 적용하면 같은 모델을 최대 4배까지 작게 만들 수 있고, 속도는 오히려 2배 빨라지면서 정확도 손실은 고작 5~10%에 불과합니다.
양자화란 무엇인가 — 숫자를 압축하는 기술
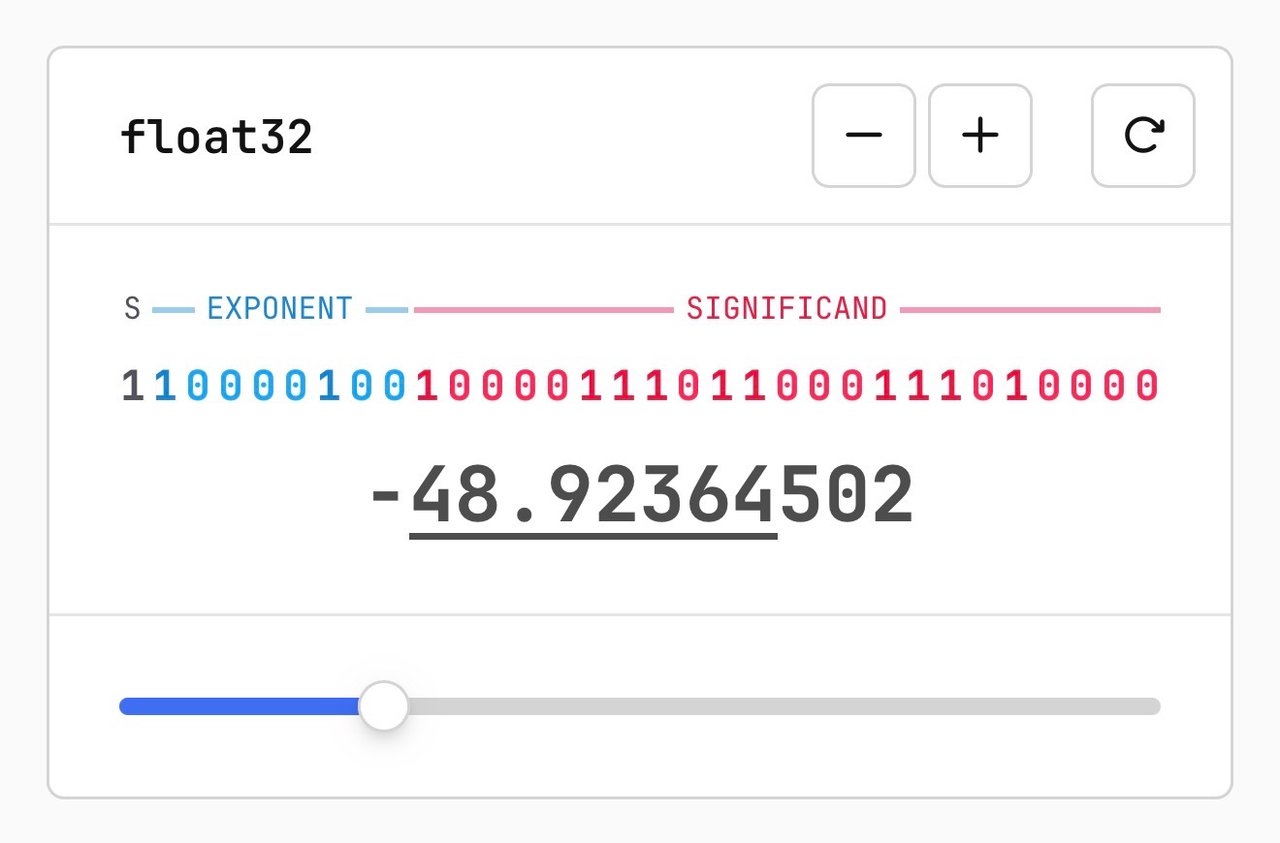
AI 모델은 수십억 개의 파라미터로 이루어져 있고, 각 파라미터는 하나의 숫자입니다. 기본적으로 이 숫자들은 16비트 부동소수점(16-bit float) 형식으로 저장됩니다. 16비트라는 것은 하나의 숫자를 표현하기 위해 16개의 비트(0 또는 1)를 사용한다는 뜻입니다.
양자화는 이 16비트 숫자들을 더 적은 비트로 표현하는 압축 기술입니다. 8비트로 줄이면 용량이 절반으로, 4비트로 줄이면 4분의 1로 줄어듭니다. 물론 숫자를 단순히 잘라내면 정보 손실이 생기지만, 영리한 스케일링(scaling, 값의 범위를 조정하는 것) 방식을 통해 손실을 최소화합니다.
양자화는 보통 32~256개의 파라미터를 하나의 블록(block)으로 묶어서 수행합니다. 블록이 클수록 추가로 저장해야 하는 메타데이터(오버헤드)는 줄어들지만 오류는 늘어납니다. 블록이 작을수록 정밀하지만 추가 저장 공간이 필요합니다.
대칭 vs 비대칭 — 어떤 방식이 더 정확한가
양자화를 구현하는 방식에는 크게 두 가지가 있습니다.
대칭 양자화(Symmetric Quantization)는 데이터의 최대 절대값(maximum absolute value)을 기준으로 스케일링하는 방식입니다. 가장 단순하고 구현이 쉽지만, 데이터 분포가 한쪽으로 치우쳐 있을 때 비효율이 발생합니다.
비대칭 양자화(Asymmetric Quantization)는 데이터의 중점(midpoint)을 기준으로 스케일링합니다. 실제 AI 모델의 가중치(weight) 분포는 대부분 0을 중심으로 약간 비대칭적이기 때문에, 비대칭 방식이 대칭 방식 대비 평균 오류를 약 50% 낮출 수 있습니다. 정밀도가 중요한 작업일수록 비대칭 방식이 훨씬 유리합니다.
수치로 보는 품질 vs 속도 트레이드오프
실제로 양자화를 적용했을 때 성능이 얼마나 달라지는지 구체적인 수치로 살펴보겠습니다. 아래 표는 동일한 모델을 비트 수에 따라 변환했을 때의 차이를 정리한 것입니다.
| 구분 | 원본 16bit | 8bit 양자화 | 4bit 양자화 |
|---|---|---|---|
| 모델 크기 | 159.4 GB | 약 80 GB | 약 40 GB |
| 속도 (M1 Max) | 기준 | 32.36 tok/s | 43.32 tok/s |
| 속도 (H100) | 기준 | — | 175.70 tok/s |
| 정확도 손실 (perplexity) | 기준 | +0.1% | +4.6% |
| GPQA Diamond 벤치마크 | 66.7% | — | 62.6% |
여기서 퍼플렉서티(Perplexity)란 AI가 텍스트를 예측하는 정확도를 나타내는 지표로, 수치가 낮을수록 좋습니다. 16bit에서 8bit로 변환하면 퍼플렉서티 변화가 +0.1%에 불과해 품질 손실이 거의 없습니다. 4bit로 가면 +4.6% 손실이 생기지만, 이는 원본 대비 약 90%의 품질을 유지한다는 뜻입니다.
속도 면에서도 주목할 점이 있습니다. 8bit 모델은 M1 Max 기준 초당 32.36 토큰(token, AI가 한 번에 처리하는 텍스트 단위)을 생성하는 반면, 4bit 모델은 43.32 tok/s로 오히려 더 빠릅니다. 데이터가 작아질수록 메모리 대역폭(bandwidth, 데이터를 전송하는 속도) 부담이 줄어들기 때문입니다. H100 같은 고성능 GPU에서는 4bit 비대칭 방식으로 175.70 tok/s라는 놀라운 속도도 달성 가능합니다.
GPQA Diamond(Graduate-Level Google-Proof Q&A, 고급 AI 능력 평가 벤치마크)에서는 원본 66.7%에서 4bit 변환 후 62.6%로 약 4.1% 하락했습니다. 실용적인 대부분의 작업에서는 이 정도 차이가 크게 느껴지지 않는 수준입니다.
'슈퍼 가중치' — 단 하나가 모든 것을 바꾼다
양자화를 이해할 때 빠트릴 수 없는 개념이 있습니다. 바로 '슈퍼 가중치(super weight)'입니다.
AI 모델의 수십억 개 파라미터 중에는 극소수이지만 모델의 동작 전체에 결정적인 영향을 미치는 특별한 값들이 존재합니다. 이 슈퍼 가중치는 일반적인 파라미터보다 훨씬 큰 절대값을 가지며, 모델이 올바른 언어를 생성하는 데 핵심적인 역할을 합니다.
놀라운 사실은, 슈퍼 가중치 단 하나만 제거하거나 잘못 양자화해도 모델이 완전히 무의미한 결과를 출력한다는 것입니다. 마치 정교한 기계에서 핵심 부품 하나를 빼내면 전체가 작동을 멈추는 것과 같습니다.
이 때문에 고급 양자화 기법에서는 슈퍼 가중치를 별도로 식별하고, 이들만큼은 높은 비트 수(예: 16bit)로 유지하면서 나머지를 4bit로 줄이는 혼합 정밀도(mixed precision) 방식을 사용하기도 합니다. 이를 통해 전체 모델 크기를 최소화하면서도 품질을 최대한 보존할 수 있습니다.
브라우저에서 직접 해보기
이 모든 개념을 추상적으로 설명하는 것보다, 직접 눈으로 보고 조작하는 것이 훨씬 효과적입니다. ngrok의 엔지니어 Sam Rose는 양자화의 원리를 브라우저에서 직접 체험할 수 있는 인터랙티브 에세이(interactive essay)를 공개했습니다.
이 에세이에서는 다음을 직접 체험할 수 있습니다.
- 부동소수점(float) 숫자의 이진(binary) 표현을 직접 비트 단위로 조작하기
- 대칭·비대칭 양자화가 실제로 어떻게 오류를 줄이는지 시각화
- 블록 크기를 바꿔가며 오버헤드와 정확도의 트레이드오프 확인
- 슈퍼 가중치를 제거했을 때 모델 출력이 어떻게 망가지는지 확인
Simon Willison(시몬 윌리슨, 유명 오픈소스 개발자)도 이 에세이를 자신의 블로그에서 극찬하며 소개했습니다. 특히 float의 이진 표현을 직접 조작하는 부분이 학습에 매우 효과적이라고 평가했습니다.
내 컴퓨터에서 양자화 AI를 돌리려면
양자화된 모델을 실제로 로컬(local, 자신의 컴퓨터)에서 실행하고 싶다면 어떻게 해야 할까요?
가장 널리 사용되는 방법은 llama.cpp와 Ollama입니다. 이 두 도구는 GGUF(GPT-Generated Unified Format) 또는 GGML 형식으로 배포되는 양자화 모델을 지원하며, Apple Silicon(M1/M2/M3), NVIDIA GPU, AMD GPU 등 다양한 환경에서 실행할 수 있습니다.
실용적인 권장 사항을 정리하면 다음과 같습니다.
- RAM 8~16GB: 7B~13B 파라미터 모델의 4bit 양자화 버전 사용 권장
- RAM 32~64GB: 30B~70B 파라미터 모델의 4bit 양자화 버전 사용 가능
- RAM 64GB 이상 또는 Apple Silicon: 70B 모델의 8bit 버전도 충분히 실행 가능
Hugging Face나 Ollama 라이브러리에서 모델 이름 옆에 Q4_K_M, Q8_0 같은 표기가 붙어 있는 것을 볼 수 있는데, 이것이 바로 양자화 방식을 나타냅니다. Q4는 4비트, Q8은 8비트를 의미하며, K_M은 k-quants 방식의 중간(medium) 품질을 나타냅니다.
양자화 덕분에 최신 AI 모델이 더 이상 거대 클라우드 기업의 전유물이 아닌, 개인 개발자와 연구자 모두가 접근할 수 있는 기술이 되어가고 있습니다. 159GB짜리 AI가 40GB로 줄어들고도 90% 이상의 성능을 유지한다는 사실은, AI 민주화(democratization)의 가능성을 현실로 보여주는 강력한 증거입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기