Voxtral TTS 무료 공개 — AI 음성복제, ElevenLabs 이기고 3초 샘플로 완성
Mistral AI의 Voxtral TTS, 블라인드 테스트에서 ElevenLabs 압도(68% vs 32%). 3초 음성 샘플만으로 목소리 복제, 16GB GPU면 완전 무료. API는 1,000자당 21원 — 오픈소스 TTS의 게임체인저.
• Mistral AI가 텍스트를 사람 목소리로 바꿔주는 AI 모델 Voxtral TTS를 오픈 웨이트(누구나 내려받아 쓸 수 있는 형태)로 공개했습니다
• 3초짜리 음성 샘플만 있으면 내 목소리를 복제할 수 있고, 사람이 듣고 비교했을 때 ElevenLabs보다 자연스럽다는 결과가 나왔습니다
• 16GB 이상 GPU가 있으면 내 컴퓨터에서 직접 돌릴 수 있고, API로는 1,000자당 약 21원에 쓸 수 있습니다
ElevenLabs를 이긴 무료 AI 음성복제 모델이 나왔다
유튜브 나레이션, 팟캐스트, 고객 응대 음성을 만들려면 지금까지는 ElevenLabs 같은 유료 TTS(텍스트 음성 변환) 서비스가 사실상 유일한 선택지였습니다. 월 구독료가 최소 5달러, 프로 플랜은 22달러입니다. 음성 복제 기능을 쓰려면 더 비쌉니다.
Mistral AI가 3월 23일 공개한 Voxtral TTS는 이 시장의 판을 바꿀 수 있는 모델입니다. 40억 개의 파라미터(AI 모델의 학습된 지식 크기)를 가진 텍스트-음성 변환 모델로, 오픈 웨이트 — 즉 누구나 내려받아 자기 컴퓨터에서 돌릴 수 있는 형태로 HuggingFace에 공개됐습니다.
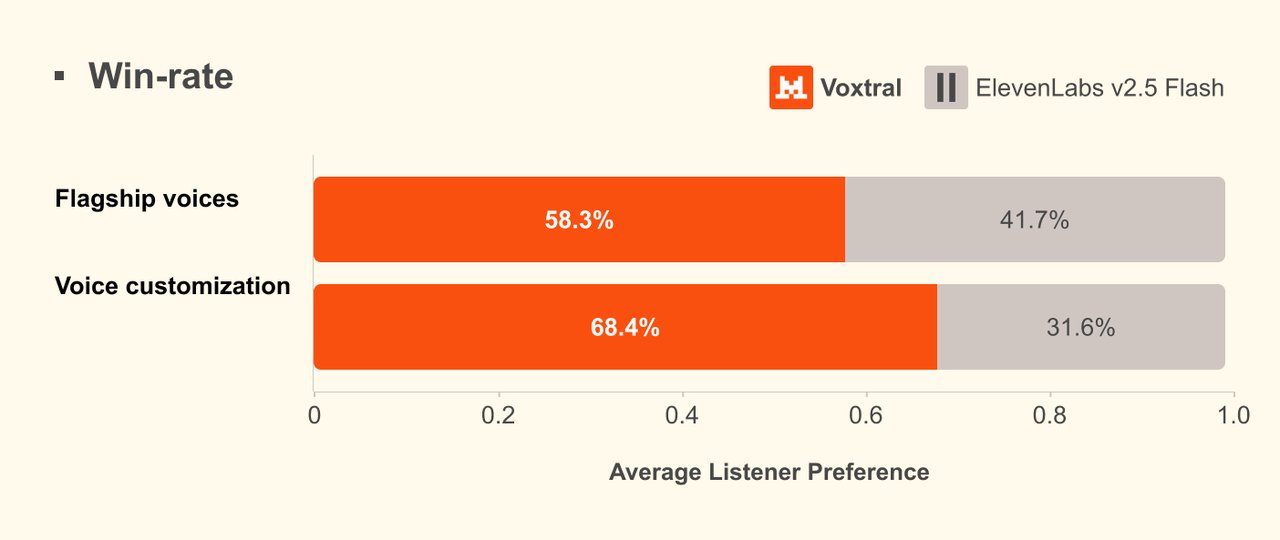
원어민 평가자를 대상으로 한 블라인드 테스트에서 Voxtral은 기본 음성 자연스러움 58.3% 대 41.7%, 음성 복제 품질 68.4% 대 31.6%로 ElevenLabs Flash v2.5를 이겼습니다. 특히 음성 복제 부문에서 2배 이상의 차이가 난 것이 눈에 띕니다.
3초 음성이면 내 목소리가 된다
Voxtral TTS의 가장 눈에 띄는 기능은 3초짜리 음성 샘플만으로 목소리를 복제하는 것입니다. 말하는 속도, 억양, 감정 표현까지 그대로 따라합니다. 짧은 음성 메시지 하나만 있으면 내 목소리로 대본을 읽게 할 수 있는 셈입니다.
더 놀라운 건 다른 언어로도 자연스럽게 변환된다는 점입니다. 예를 들어 프랑스어 음성 샘플을 넣으면, 프랑스 억양이 자연스럽게 묻어나는 영어 음성을 만들 수 있습니다. Mistral은 이걸 "제로샷 크로스링구얼 적응"이라 부르는데, 쉽게 말해 한 번도 학습하지 않은 언어 조합도 자연스럽게 처리하는 기술입니다.
Voxtral TTS 지원 언어와 기본 사양
기본 제공 음성: 20가지 프리셋
출력 음질: 24kHz
지원 형식: WAV, MP3, FLAC, AAC, Opus, PCM
응답 속도: 70밀리초(0.07초) — 거의 실시간
한 번에 생성 가능한 길이: 최대 2분
모델 구조는 세 부분으로 나뉩니다. 34억 파라미터 트랜스포머 디코더(문장을 이해하는 부분), 3억 9천만 파라미터 음향 트랜스포머(자연스러운 발음을 만드는 부분), 3억 파라미터 오디오 코덱(최종 음성 파일을 만드는 부분)입니다.
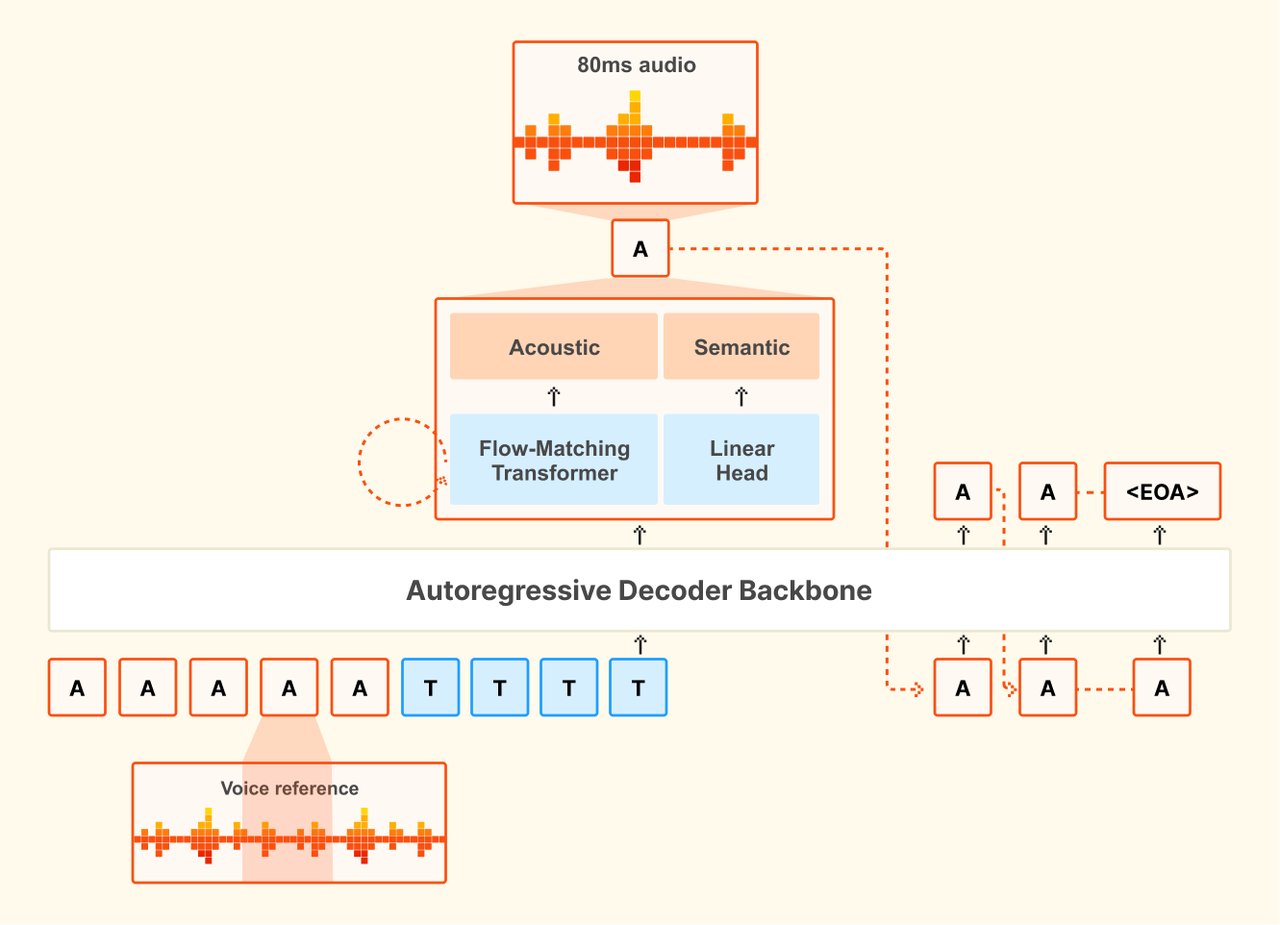
내 컴퓨터에서 직접 돌리는 방법
16GB 이상의 GPU 메모리가 있는 컴퓨터라면 Voxtral TTS를 직접 설치해서 무료로 사용할 수 있습니다. NVIDIA RTX 4060 Ti(16GB) 이상이면 충분합니다.
# 설치 (vLLM Omni 사용)
uv pip install -U vllm
uv pip install git+https://github.com/vllm-project/vllm-omni.git --upgrade
# 서버 실행
vllm serve mistralai/Voxtral-4B-TTS-2603 --omni서버가 실행되면 Python 코드 몇 줄로 음성을 만들 수 있습니다:
import io, httpx, soundfile as sf
payload = {
"input": "Hello, this is a test of Voxtral TTS.",
"model": "mistralai/Voxtral-4B-TTS-2603",
"response_format": "wav",
"voice": "causal_male", # 20가지 프리셋 중 선택
}
response = httpx.post(
"http://localhost:8000/v1/audio/speech",
json=payload, timeout=120.0
)
audio, sr = sf.read(io.BytesIO(response.content), dtype="float32")
print(f"생성 완료: {len(audio)} 샘플, {sr} Hz")NVIDIA H200 GPU에서의 벤치마크 결과를 보면, 동시 요청 1개일 때 70밀리초 지연에 초당 119자를 처리하고, 동시 요청 32개로 올리면 초당 1,430자까지 처리량이 올라갑니다. 실시간 AI 음성 에이전트 구축에도 충분한 속도입니다. AI 에이전트를 직접 만들어보고 싶다면 에이전트 팀 구성 실전 가이드를 참고하세요.
GPU가 없다면 — API로 바로 쓰기
고사양 컴퓨터가 없어도 괜찮습니다. Mistral API를 통해 1,000자당 $0.016(약 21원)에 사용할 수 있습니다. ElevenLabs 프로 플랜(월 $22)과 비교하면 필요한 만큼만 쓰는 종량제라 소규모 프로젝트에 훨씬 경제적입니다.
Mistral Studio 데모 페이지에서 바로 테스트해볼 수 있고, HuggingFace 데모에서도 직접 들어볼 수 있습니다.
이런 분에게 유용합니다
알아둘 점 — 한국어는 아직 미지원
라이선스는 CC BY-NC 4.0입니다. 비상업적 용도(개인 프로젝트, 연구, 학습)에는 완전 무료이지만, 상업적으로 쓰려면 Mistral API를 통해 유료로 사용해야 합니다.
현재 한국어는 지원 언어에 포함되어 있지 않습니다. 영어, 프랑스어, 독일어, 스페인어, 네덜란드어, 포르투갈어, 이탈리아어, 힌디어, 아랍어 — 총 9개 언어만 지원됩니다. 한국어 음성 복제가 필요하다면 아직은 다른 도구를 찾아야 합니다.
그래도 영어 콘텐츠를 만드는 분이라면 지금 당장 써볼 만한 가치가 충분합니다. ElevenLabs의 강력한 오픈소스 대안이 등장한 것은 이번이 처음이고, 블라인드 테스트에서 유료 서비스를 이긴 것은 상당히 의미 있는 결과입니다. Mistral은 이미 74만 건 다운로드를 기록한 음성 인식 모델 Voxtral Mini도 함께 운영 중이어서, 음성 인식 + 음성 생성을 하나의 파이프라인으로 묶을 수도 있습니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | AI 쇼츠 자동화 가이드 | 에이전트 팀 구성 실전 | AI 뉴스 더보기
출처