Whisper 오류율 7%인데 이 무료 AI는 5%입니다 — Cohere Transcribe
회의 녹음을 글로 바꿀 때 Whisper보다 정확하고 3.6배 빠른 무료 AI가 나왔습니다. Cohere Transcribe는 한국어 포함 14개 언어를 지원하며, HuggingFace 음성인식 리더보드 1위(WER 5.42%)를 기록했습니다.
Cohere Transcribe는 음성을 글로 바꿔주는 AI 모델입니다. OpenAI Whisper보다 오류율이 27% 낮고, 처리 속도는 3.6배 빠릅니다. 한국어 포함 14개 언어를 지원하며, Apache 2.0 오픈소스 라이선스로 무료입니다. 내 컴퓨터에서 직접 돌릴 수도 있고, 웹 데모에서 바로 체험할 수도 있습니다.
Whisper 대신 써야 하는 이유 — 숫자로 비교합니다
음성인식 AI의 정확도는 WER(단어 오류율, 100단어 중 몇 개를 틀리는지)로 측정합니다. 숫자가 낮을수록 좋습니다. Cohere Transcribe는 HuggingFace Open ASR 리더보드에서 1위를 차지했습니다.
| 모델 | 평균 오류율(WER) ↓ | 비고 |
|---|---|---|
| Cohere Transcribe | 5.42% | 1위 |
| Zoom Scribe v1 | 5.47% | 비공개 |
| IBM Granite 4.0 1B | 5.52% | 오픈소스 |
| ElevenLabs Scribe v2 | 5.83% | 유료 |
| Qwen3-ASR-1.7B | 5.76% | 오픈소스 |
| OpenAI Whisper Large v3 | 7.44% | 오픈소스 |
Whisper Large v3와 비교하면 오류율이 27% 낮습니다. 유료 서비스인 ElevenLabs Scribe v2(5.83%)보다도 정확합니다. 회의 녹음, 인터뷰 정리, 팟캐스트 자막 — 어디에 쓰든 틀리는 단어가 눈에 띄게 줄어듭니다.
정확할 뿐 아니라 3.6배 빠릅니다
음성인식에서 속도는 RTFx(실시간 대비 처리 배수)로 측정합니다. 1분짜리 음성 파일을 0.1초에 처리하면 RTFx는 600입니다. 숫자가 클수록 빠릅니다.
Cohere Transcribe의 RTFx는 525입니다. 쉽게 말하면:
1시간짜리 회의 녹음 → 약 7초에 텍스트 완성
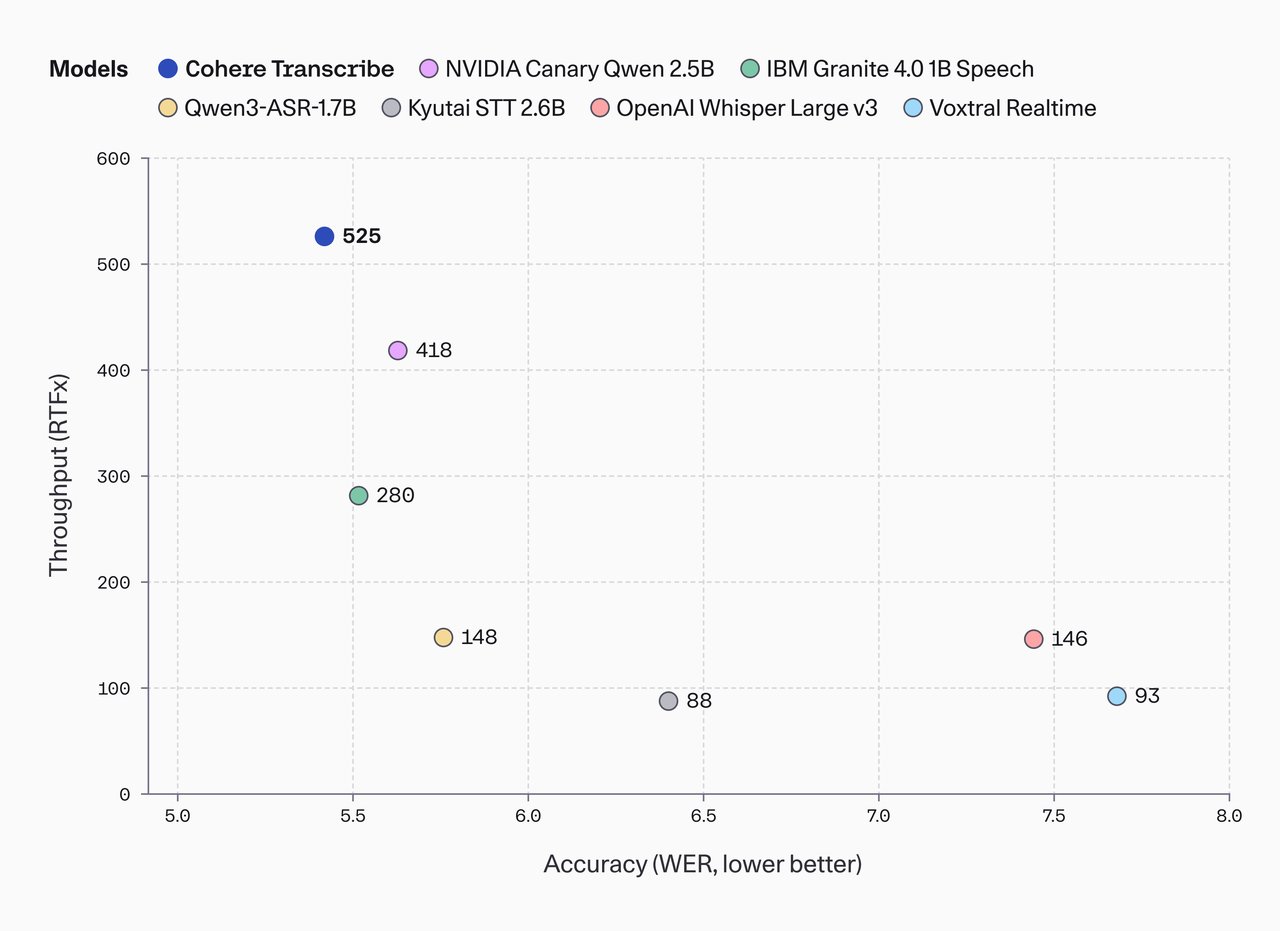
위 차트에서 왼쪽 위에 있을수록 정확하고 빠른 모델입니다. Cohere Transcribe(파란 점, RTFx 525)가 압도적으로 좌상단에 위치합니다. OpenAI Whisper Large v3(분홍 점)는 RTFx 146으로, Cohere의 3.6분의 1 속도입니다. NVIDIA Canary Qwen 2.5B(보라 점, RTFx 418)도 정확도에서 밀립니다.
이 속도라면 2시간짜리 강의 전체를 14초에 텍스트로 바꿀 수 있습니다. 어제 소개한 insanely-fast-whisper가 Whisper의 속도를 끌어올리는 '튜닝'이었다면, Cohere Transcribe는 처음부터 빠르게 설계된 '신형 엔진'입니다.
사람이 직접 들어봐도 Cohere가 이깁니다
기계적 수치만으로는 실제 품질을 판단하기 어려울 수 있습니다. Cohere는 전문 평가자에게 각 모델의 결과물을 비교시키는 인간 선호도 평가도 진행했습니다. 정확성, 의미 보존, 사람 이름·회사명 같은 고유명사 인식, 형식 등을 기준으로 어느 쪽 결과물이 더 나은지 고르게 했습니다.
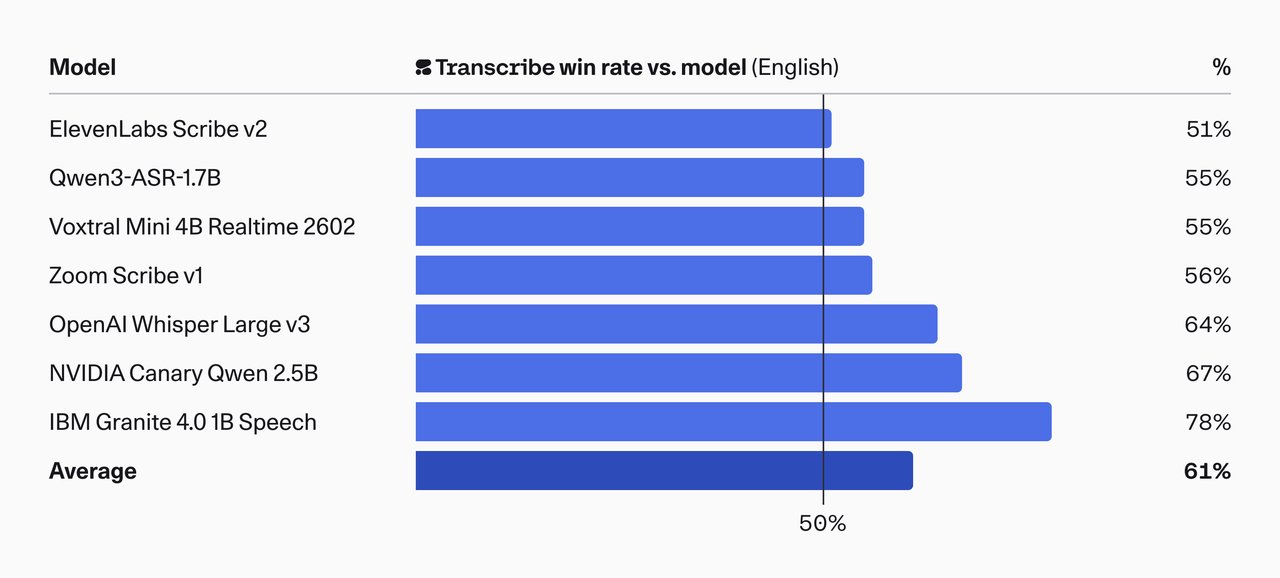
결과는 평균 61% 승률입니다. IBM Granite 4.0 대비 78%, NVIDIA Canary Qwen 2.5B 대비 67%로 큰 차이를 보였습니다. 50% 기준선(동률)을 모든 모델 대비 넘었다는 것은, 사람이 직접 비교해도 Cohere Transcribe의 결과물이 더 자연스럽고 정확하다는 뜻입니다.
한국어 음성인식도 됩니다 — 14개 언어 지원
영어 전용 모델은 많지만, 한국어까지 지원하는 오픈소스 음성인식 모델은 드뭅니다. Cohere Transcribe는 한국어를 포함해 영어, 프랑스어, 독일어, 이탈리아어, 스페인어, 포르투갈어, 그리스어, 네덜란드어, 폴란드어, 아랍어, 베트남어, 중국어, 일본어까지 14개 언어를 지원합니다.
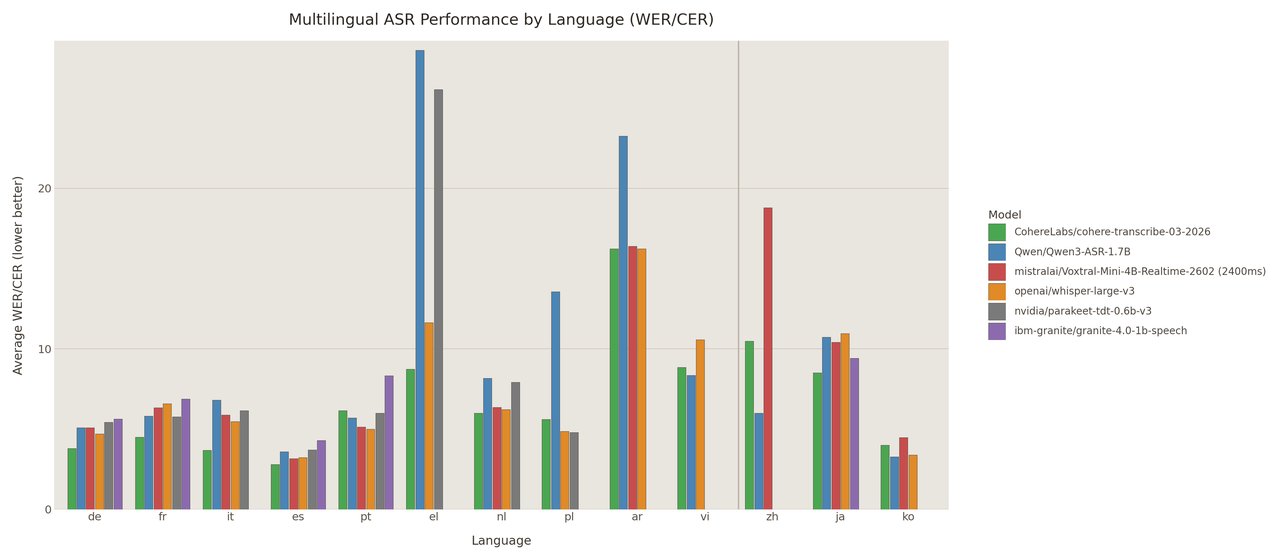
위 차트의 맨 오른쪽 'ko'(한국어) 항목을 보면, Cohere Transcribe(초록색 막대)가 대부분의 경쟁 모델보다 낮은 오류율을 보입니다. 한국어 회의록 작성, 인터뷰 정리, 강의 자막 생성에 바로 활용할 수 있습니다.
내 컴퓨터에서 돌려보기
모델 크기가 20억 개 파라미터(약 4~8GB)로, 일반 그래픽카드에서도 돌릴 수 있습니다. NVIDIA GPU가 있다면 가장 좋지만, CPU에서도 작동합니다(다만 느립니다).
1단계: 설치
pip install "transformers>=4.56,<5.3" torch huggingface_hub soundfile librosa sentencepiece protobuf2단계: 한국어 음성 파일 변환
import torch
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
model_id = "CohereLabs/cohere-transcribe-03-2026"
device = "cuda:0" if torch.cuda.is_available() else "cpu"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, trust_remote_code=True
).to(device)
model.eval()
# 내 음성 파일 경로를 넣으면 됩니다
texts = model.transcribe(
processor=processor,
audio_files=["meeting_recording.wav"],
language="ko" # 한국어
)
print(texts[0])language 값을 바꾸면 다른 언어도 됩니다: "en"(영어), "ja"(일본어), "zh"(중국어), "fr"(프랑스어) 등.
3단계 (선택): vLLM 서버로 대량 처리
여러 파일을 빠르게 처리하고 싶다면 vLLM(대규모 AI 모델을 빠르게 서빙하는 도구)으로 서버를 띄울 수 있습니다. Cohere 팀이 직접 vLLM에 최적화 코드를 기여해서, 최대 2배 추가 속도 향상이 가능합니다.
# vLLM 서버 시작
vllm serve CohereLabs/cohere-transcribe-03-2026 --trust-remote-code
# 음성 파일 전송 (다른 터미널에서)
curl -X POST http://localhost:8000/v1/audio/transcriptions \
-F "file=@meeting.wav" \
-F "model=CohereLabs/cohere-transcribe-03-2026"코딩 없이 바로 체험하기
설치가 부담스러우면 두 가지 방법이 있습니다:
웹 데모 — HuggingFace Space에서 음성 파일을 업로드하면 바로 결과를 확인할 수 있습니다.
Cohere API 무료 티어 — dashboard.cohere.com에서 회원가입하면 무료로 API를 사용할 수 있습니다. 실험과 프로토타이핑에 충분한 양입니다.
알아둘 점 3가지
1. 언어를 직접 지정해야 합니다 — 자동 언어 감지 기능이 없습니다. 한국어 음성이면 language="ko"로 명시해야 합니다. 한국어와 영어가 섞인 대화에서는 정확도가 떨어질 수 있습니다.
2. 타임스탬프와 화자 구분이 안 됩니다 — "00:03:25 김 과장: ~" 같은 출력은 불가능합니다. 순수 텍스트만 나옵니다. 화자 구분이 필요하면 별도 도구를 조합해야 합니다.
3. 조용한 구간에서 환각(hallucination)이 발생할 수 있습니다 — 음성이 없는 구간에서 존재하지 않는 단어를 만들어내는 현상입니다. 녹음 전에 배경 소음을 제거하거나, VAD(음성 활동 감지, 말하는 부분만 자동으로 골라내는 기술)를 앞에 붙이면 해결됩니다.
50만 시간의 데이터로 훈련된 구조
Cohere Transcribe는 50만 시간의 음성-텍스트 쌍 데이터로 훈련됐습니다. 아키텍처는 Fast-Conformer 기반 인코더-디코더 구조입니다. 쉽게 설명하면, '듣는 부분'(인코더)에 전체 파라미터의 90% 이상을 집중시켜 음성을 정확히 이해하게 하고, '쓰는 부분'(디코더)은 가볍게 만들어 텍스트 생성 속도를 높인 구조입니다.
Cohere는 이 모델을 자사의 기업용 AI 플랫폼 North에 통합할 계획입니다. 회의 자동 요약, 고객 상담 분석, 실시간 자막 생성 같은 기업 현장 활용이 목표입니다. 개인은 오픈소스로 무료 사용, 기업은 Model Vault라는 관리형 서비스를 유료로 이용하는 구조입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기