AI 음성 텍스트 변환 31분 → 98초 — insanely-fast-whisper 무료 사용법
회의 녹음 150분을 98초에 텍스트로 변환합니다. 속도는 19배, 정확도는 Whisper와 동일. 배치 처리·Flash Attention 2 기반 무료 오픈소스. 터미널 한 줄 설치, Mac Apple Silicon 지원.
AI 음성 텍스트 변환 도구 OpenAI Whisper(음성을 텍스트로 바꿔주는 AI)로 2시간 반짜리 오디오 파일을 변환하면 약 31분이 걸립니다. insanely-fast-whisper는 같은 작업을 98초에 끝냅니다. 정확도는 동일합니다. 무료 오픈소스이고, 터미널에서 명령어 한 줄이면 설치됩니다. 오늘 GitHub 트렌딩에서 하루 만에 스타 1,400개 이상을 받으며 주목받고 있습니다.

AI 음성인식이 150분에서 98초로 줄어드는 원리
일반 Whisper는 오디오를 처음부터 끝까지 순서대로 처리합니다. 책을 한 줄씩 읽는 것과 같습니다. insanely-fast-whisper는 두 가지 기술로 이 과정을 획기적으로 줄였습니다.
1. 배치 처리(Batch Processing) — 오디오를 24개 조각으로 나눠서 동시에 처리합니다. 한 줄씩 읽던 책을 24페이지씩 한꺼번에 읽는 것과 같습니다.
2. Flash Attention 2 — GPU(그래픽카드)가 데이터를 처리하는 방식을 최적화한 기술입니다. 같은 하드웨어에서 계산 속도가 몇 배 빨라집니다. 메모리도 적게 씁니다.
결과적으로 실시간 대비 92배 빠른 속도를 달성합니다. 150분짜리 오디오를 처리하는 데 150 ÷ 92 ≈ 1.6분, 즉 약 98초면 끝납니다. 경량 모델인 Distil-Whisper를 쓰면 실시간 대비 100배 이상까지 올라갑니다.
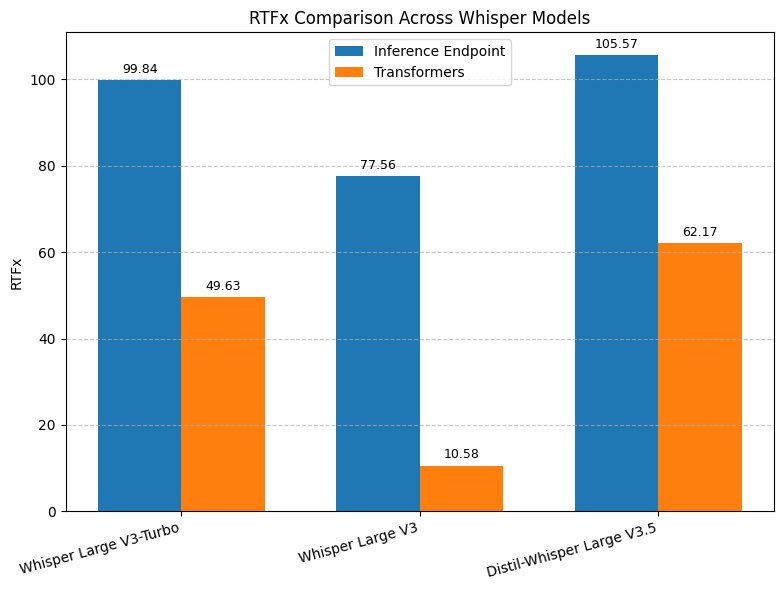
위 차트에서 파란색이 최적화 후, 주황색이 기본 속도입니다. Whisper Large V3 기준으로 기존 10.58배에서 77.56배로 약 7.3배 빨라졌습니다. Distil-Whisper Large V3.5는 105배까지 올라갑니다.
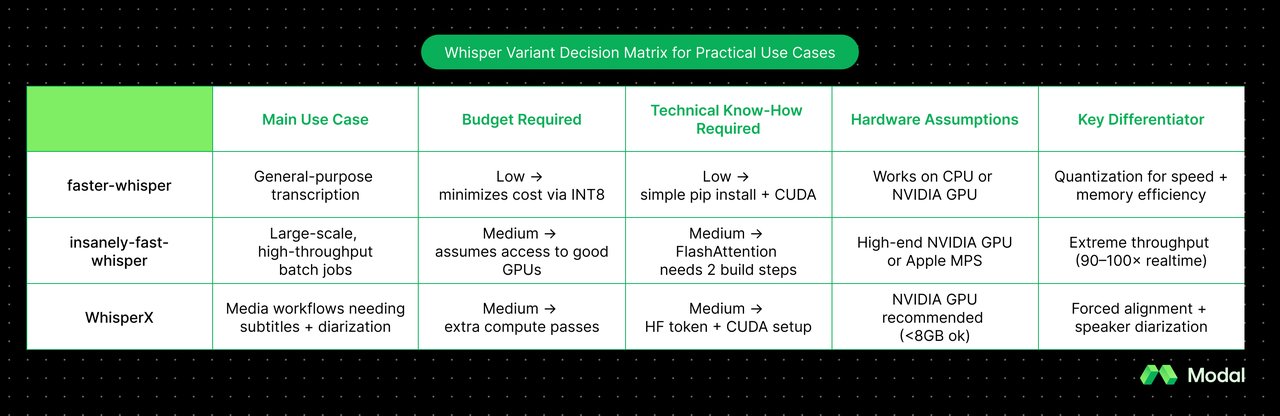
faster-whisper, insanely-fast-whisper, WhisperX — 뭘 써야 하나
Whisper 기반 음성인식 도구는 세 가지가 대표적입니다. 모두 OpenAI Whisper와 동일한 정확도를 유지하면서 속도를 개선한 도구들입니다. 차이는 속도, 필요한 하드웨어, 그리고 추가 기능에 있습니다.

faster-whisper — 가장 범용적인 선택입니다. CPU에서도 돌아가고, 4~6GB 그래픽 메모리면 충분합니다. RTX 3070 Ti 기준 실시간 대비 12배, 배치 처리 시 49배까지 가능합니다. 그래픽카드가 없거나 보급형이라면 이것을 추천합니다.
insanely-fast-whisper — 속도가 최우선이라면 이 도구입니다. A100 GPU에서 실시간 대비 92배, Distil 모델로는 100배 이상입니다. 고성능 GPU(NVIDIA A100, H100 등)나 Mac Apple Silicon이 있다면 최고의 선택입니다. GitHub 스타 1만 600개.
WhisperX — "누가 말했는지"까지 구분해야 한다면 이 도구입니다. 화자 분리(회의에서 누가 어떤 말을 했는지 자동 구분)와 단어 단위 시간 표시를 기본 지원합니다. 8GB 그래픽 메모리면 충분하고, 실시간 대비 70배 속도입니다. 회의록이나 인터뷰 정리에 가장 적합합니다.
insanely-fast-whisper 설치 방법 — 터미널에서 5분이면 시작
insanely-fast-whisper는 Python 패키지로 배포됩니다. 설치는 명령어 한 줄입니다.
pipx install insanely-fast-whisper설치 후 오디오 파일을 넣으면 바로 변환이 시작됩니다.
# 기본 사용법 — 오디오 파일을 텍스트로 변환
insanely-fast-whisper --file-name meeting.mp3
# Flash Attention 2 활성화 (더 빠르게)
insanely-fast-whisper --file-name meeting.mp3 --flash True
# 한국어 오디오 변환
insanely-fast-whisper --file-name meeting.mp3 --language ko
# 영어 오디오를 한국어로 번역하면서 변환
insanely-fast-whisper --file-name podcast.mp3 --task translate출력은 JSON 형식으로 저장됩니다. 텍스트 내용과 함께 시간 정보(몇 분 몇 초에 어떤 말이 나왔는지)도 포함됩니다.
Mac Apple Silicon에서 insanely-fast-whisper 설치하기
Apple Silicon(M1/M2/M3/M4) Mac에서도 사용할 수 있습니다. 다만 GPU 메모리가 통합 메모리(Unified Memory) 방식이라, 배치 사이즈를 줄여야 안정적으로 동작합니다.
# Mac Apple Silicon 설정
insanely-fast-whisper --file-name meeting.mp3 --device-id mps --batch-size 4A100 GPU의 98초보다는 느리지만, 기본 Whisper보다 확실히 빠릅니다. 배치 사이즈 4로도 여러 조각을 동시에 처리하는 효과가 있습니다.
회의에서 누가 말했는지도 자동으로 구분합니다
insanely-fast-whisper는 화자 분리(Speaker Diarization) 기능도 지원합니다. 회의 녹음에서 "이 부분은 A가 말한 것, 저 부분은 B가 말한 것"을 자동으로 구분해줍니다. Pyannote.audio 모델을 활용합니다.
# 화자 분리 사용 (Hugging Face 토큰 필요)
insanely-fast-whisper --file-name meeting.mp3 --hf-token YOUR_HF_TOKEN --diarize
# 참석자가 3명이라고 알려주면 더 정확합니다
insanely-fast-whisper --file-name meeting.mp3 --hf-token YOUR_HF_TOKEN --diarize --num-speakers 3화자 분리를 사용하려면 Hugging Face에서 무료 계정을 만들고 토큰을 발급받으면 됩니다.
GPU가 없는 경우 — 음성 변환 AI 두 가지 대안
insanely-fast-whisper는 NVIDIA GPU나 Mac Apple Silicon이 필요합니다. 그래픽카드가 없는 컴퓨터에서 쓰려면 두 가지 방법이 있습니다.
방법 1: faster-whisper 사용 — CPU에서도 작동하는 대안입니다. pip install faster-whisper로 설치합니다. 속도는 insanely-fast-whisper보다 느리지만, 일반 Whisper보다 4배 빠르고 메모리도 절반만 씁니다. GitHub 저장소
방법 2: Google Colab 무료 GPU — insanely-fast-whisper를 그대로 쓰되, 내 컴퓨터 대신 Google의 무료 GPU(T4)를 빌려 쓰는 방법입니다. GitHub 저장소에 Colab 노트북이 포함되어 있어서, 클릭 몇 번이면 바로 실행할 수 있습니다.
정리하면 이렇습니다.
고성능 NVIDIA GPU 보유 → insanely-fast-whisper (최고 속도, 92배 실시간)
Mac Apple Silicon 보유 → insanely-fast-whisper + --device-id mps 옵션
중급 GPU + 화자 구분 필요 → WhisperX (화자 분리 + 단어 타임스탬프)
GPU 없음 / 보급형 → faster-whisper (CPU에서도 작동)
GPU 없음 + 빠른 속도 원함 → Google Colab + insanely-fast-whisper (무료 GPU)
세 도구 모두 OpenAI Whisper와 동일한 모델 가중치(AI가 학습한 지식)를 사용하므로, 정확도에는 차이가 없습니다. 빠르다고 대충 듣는 게 아닙니다. 차이는 오직 속도와 필요한 하드웨어뿐입니다.
insanely-fast-whisper는 오늘 GitHub 트렌딩에서 하루 만에 스타 1,400개 이상을 받았습니다. 팟캐스트 자막 생성, 유튜브 영상 자막, 회의록 정리, 인터뷰 전사, 강의 녹음 텍스트 변환 등 음성을 텍스트로 바꿔야 하는 모든 작업에서 시간을 획기적으로 줄여줍니다. 변환한 텍스트를 콘텐츠 제작에 활용하고 싶다면 AI 쇼츠 자동화 가이드에서 영상 제작 워크플로우 전체를 자동화하는 방법을 확인해보세요. MIT 라이선스로 상업적 사용도 자유롭습니다.
관련 콘텐츠 — AI 쇼츠 자동화 가이드 | Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기
출처