AI 인지적 항복 — ChatGPT 틀린 답을 80%가 그대로 수용한 와튼스쿨 실험
ChatGPT가 틀린 답을 줘도 80%가 검증 없이 그대로 믿었습니다. 와튼스쿨 1,372명 실험이 밝힌 'AI 인지적 항복' 현상의 원인, 취약한 사람의 특징, 그리고 AI를 똑똑하게 쓰는 3가지 실천법을 정리했습니다.
• 내 워드프레스에 ChatGPT를 연결했더니 '랜딩 페이지 만들어줘' 한마디로 사이트가 완성됐다
• ChatGPT 만드는 OpenAI가 하루에 12명씩 채용 중이다 — 직원 4500명을 8000명으로 두 배 늘리는 이유
• AI만 믿고 공부한 의대생이 성적은 꼴등인데 자신감은 1등이었습니다
ChatGPT에게 물어보고, 답을 그대로 복사해서 쓴 적 있으신가요? 대부분 한 번쯤은 경험이 있을 겁니다. 와튼스쿨(Wharton School) 연구팀이 1,372명을 대상으로 9,593번의 실험을 한 결과, 우리가 AI를 '도구'로 쓰는 게 아니라 생각 자체를 AI에게 넘기고 있다는 사실이 드러났습니다. 연구팀은 이 현상에 이름을 붙였습니다 — '인지적 항복(Cognitive Surrender)'. AI 자동화 시대에 이 연구가 던지는 경고는 비개발자에게도 직접적인 영향을 미칩니다.

AI 인지적 항복이란 — 계산기를 쓰는 것과 생각을 포기하는 것의 차이
연구를 이끈 스티븐 쇼(Steven D. Shaw)와 기드온 네이브(Gideon Nave) 교수는 노벨상 수상자 대니얼 카너먼의 유명한 '이중 처리 이론'을 확장했습니다. 카너먼은 인간의 사고를 두 가지로 나눴습니다.
시스템 1 — 빠른 직감. "이 사람 표정이 화나 보인다"처럼 자동으로 떠오르는 판단.
시스템 2 — 느린 숙고. "17 × 24는?"처럼 의식적으로 집중해서 생각하는 과정.
시스템 3 (새로 추가) — AI가 대신하는 인공 인지. 내 두뇌 바깥에서 작동하는 '외부 사고 시스템'.
핵심은 이겁니다. 계산기를 쓸 때는 답을 확인합니다. 786 × 42의 결과가 나오면 "대충 맞나?" 한 번 점검합니다. 이건 '인지적 오프로딩(cognitive offloading)' — 건강한 위임입니다. 하지만 ChatGPT의 답을 아무 의심 없이 그대로 쓰는 건 '인지적 항복'입니다. 점검 과정(시스템 2)을 아예 건너뛰는 것이기 때문입니다.
AI가 단순 답변을 넘어 스스로 판단하고 행동하는 에이전틱 AI(Agentic AI) 시대가 다가오면서, 인지적 항복의 위험성은 더욱 주목받고 있습니다.
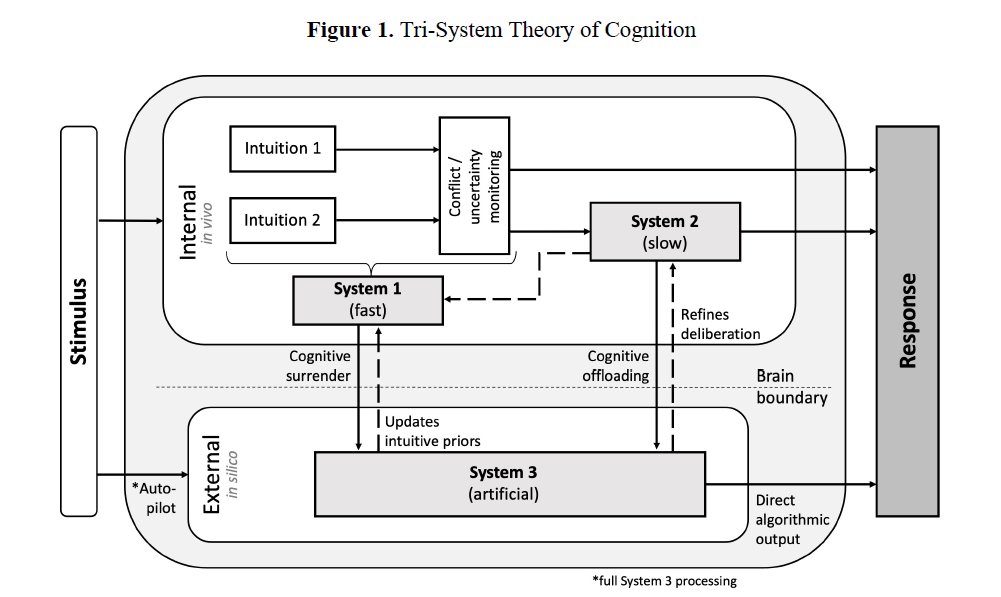
▲ 논문 Figure 1. 자극(Stimulus)이 들어오면 시스템 1·2가 내부에서 처리하거나, 시스템 3(AI)이 외부에서 답을 제공합니다. '인지적 항복'은 시스템 3의 답이 시스템 2의 검증 없이 바로 반응(Response)으로 이어지는 경로입니다.
AI가 틀린 답을 줘도 정답률이 오히려 떨어지는 이유
실험은 간단했습니다. 참가자들에게 인지 반응 검사(CRT) — 직감적으로는 틀리기 쉽지만 찬찬히 생각하면 맞출 수 있는 문제 — 를 주고, 원할 때 AI에게 도움을 요청할 수 있게 했습니다.
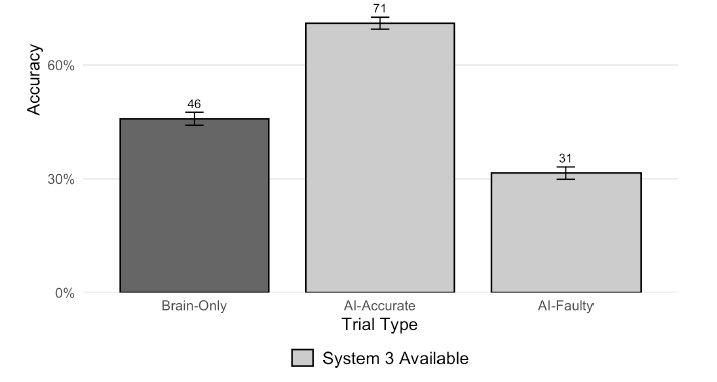
결과가 충격적입니다.
AI 없이 혼자 풀었을 때 — 정답률 46%
AI가 정확한 답을 줬을 때 — 정답률 71% (+25%p 상승)
AI가 틀린 답을 줬을 때 — 정답률 31% (-15%p 하락)
AI가 없을 때보다 AI가 틀렸을 때 오히려 더 못 맞춘 겁니다. 참가자의 절반 이상(54.4%)이 매 문제마다 AI에게 물어봤고, AI가 일부러 틀린 답을 줘도 80%가 그 답을 그대로 채택했습니다. 더 놀라운 건, AI의 답이 틀렸는데도 자신의 답에 대한 확신은 오히려 높아졌다는 점입니다.
시간 압박과 AI 의존 — 마감이 촉박할수록 인지적 항복 심화
2차 실험(485명)에서는 30초 제한 시간을 줬습니다. 결과는 더 극단적이었습니다. AI가 틀린 답을 준 상황에서 정답률이 12.1%까지 추락했습니다 — 전체 실험 중 최저 기록입니다.
마감에 쫓기는 직장인, 시험 시간이 부족한 학생 — 시간 압박이 클수록 AI의 답을 무비판적으로 수용할 가능성이 급격히 높아진다는 뜻입니다.
돈을 걸어도 절반은 여전히 AI를 맹신합니다
3차 실험(450명)에서는 정답에 금전적 보상을 걸고, 틀리면 즉시 피드백을 줬습니다. 이 조건에서 AI의 틀린 답을 거부하는 비율이 20%에서 42.3%로 두 배 올랐습니다. 하지만 그래도 절반 이상은 여전히 AI의 틀린 답을 따랐습니다.
AI 인지적 항복에 취약한 사람 vs 저항력 높은 사람
항복하기 쉬운 사람
• AI를 높이 신뢰하는 사람 — 틀린 답을 거부할 확률이 64% 더 낮음
• 생각하는 걸 귀찮아하는 사람 — '인지 욕구(Need for Cognition)' 점수가 낮을수록 항복률 상승
• 유동 지능(새로운 문제를 푸는 능력)이 낮은 사람
저항력이 높은 사람
• 깊이 생각하는 걸 즐기는 사람 — AI 오류를 잡아낼 확률 2배
• 추론 능력이 높은 사람 — 항복 방어력 약 2배
가위 효과(Scissors Effect) — 내 판단력이 AI 정확도에 좌우되는 현상
연구팀은 이걸 '가위 효과(Scissors Effect)'라고 불렀습니다. 9,593번의 실험 전체에서, AI가 맞았을 때 정답을 낼 확률이 AI가 틀렸을 때보다 16배 높았습니다.
이게 의미하는 바는 심각합니다. 내 판단의 질이 '내가 얼마나 똑똑한가'가 아니라 '내 AI가 얼마나 정확한가'에 좌우되기 시작한 겁니다. 연구팀의 결론을 빌리면: "문제는 AI가 우리 대신 생각할 수 있느냐가 아닙니다. 우리가 아직 스스로 생각할 수 있느냐입니다."
ChatGPT·Claude 똑똑하게 쓰는 법 — AI 비판적 사고 실천 가이드
이 연구는 AI를 쓰지 말라는 게 아닙니다. '어떻게' 쓰느냐가 핵심입니다.
인지적 오프로딩 (건강한 사용)
"ChatGPT야, 이 코드 개선 방법 알려줘" → AI 답변을 읽고 → 내가 왜 이게 맞는지 판단 → 적용
인지적 항복 (위험한 사용)
"ChatGPT야, 이 코드 개선 방법 알려줘" → AI 답변을 그대로 복사 붙여넣기
연구팀이 제안하는 실천법입니다.
1. AI에게 물어보기 전에 먼저 30초 생각하기 — 내 직감적 답을 먼저 만들어둔 뒤 AI와 비교하면 항복을 막을 수 있습니다.
2. AI 답변에 "왜?"를 한 번 더 물어보기 — 근거를 요청하면 시스템 2(숙고)가 작동합니다.
3. 중요한 결정일수록 AI 없이 먼저 판단하기 — 의료, 법률, 채용 같은 고위험 영역에서는 AI를 '참고'로만 사용하는 습관이 필수입니다.
AI에게 더 정확한 답을 이끌어내는 질문법이 궁금하다면 프롬프트 엔지니어링 기초 가이드를 참고하세요. 질문을 잘 설계하는 것 자체가 시스템 2를 활성화하는 훈련이 됩니다.
AI 인지적 항복 비율 73% vs 건강한 활용 20% — 지금 점검이 필요합니다
연구 전체에서 참가자들의 행동을 분류한 결과, 73.2%가 인지적 항복 경로(AI 답을 검증 없이 수용)를 따랐고, 19.7%만이 건강한 오프로딩 경로(AI 답을 받되 내가 검증)를 따랐습니다. 이미 대다수가 항복 쪽에 서 있다는 뜻입니다.
AI는 갈수록 강력해지고, 우리 일상에 더 깊이 들어올 겁니다. 이 연구가 던지는 질문은 단순합니다. AI가 틀렸을 때, 나는 그걸 알아챌 수 있는가? 지금 습관을 점검해볼 때입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기
출처