Transformer 효율 25% 개선 — Kimi Attention Residuals 핵심 분석
Transformer 구조의 25% 비효율을 Kimi(MoonshotAI) 팀이 발견했습니다. Attention Residuals로 추론 7.5점·코딩 3.1점 향상 — 기존 코드에 바로 적용 가능한 드롭인 방식입니다.
Transformer(트랜스포머) 효율을 25% 개선하는 새로운 방법이 등장했습니다. ChatGPT, Claude, Gemini — 우리가 매일 쓰는 AI는 모두 Transformer라는 같은 엔진 위에서 돌아갑니다. 2017년 구글이 발명한 이 구조는 AI 역사상 가장 중요한 발명 중 하나입니다. 그런데 이 엔진에 구조적인 낭비가 숨어 있었습니다. 중국 AI 기업 MoonshotAI(Kimi 챗봇 개발사) 연구팀 36명이 Attention Residuals라는 해법을 내놓아 같은 성능을 25% 적은 컴퓨팅으로 달성합니다.
• Transformer의 정보 전달 구조에 비효율 발견 → 25% 적은 컴퓨팅으로 같은 성능 달성
• 추론 능력 +7.5점, 코딩 능력 +3.1점, 수학 +3.6점 향상
• 기존 AI 코드에 최소한의 수정만으로 적용 가능 (드롭인 교체 방식)
• 깃허브 스타 2,200개, 해커뉴스 프런트페이지 등극
Transformer 잔여 연결(Residual Connection)의 구조적 문제
Transformer는 여러 층(layer)으로 쌓여 있습니다. 첫 번째 층은 단어의 기본 의미를, 중간 층은 문맥을, 마지막 층은 최종 답을 만듭니다. 각 층은 처리 결과를 다음 층으로 전달하는데, 이때 사용하는 방식이 잔여 연결(residual connection)입니다.
비유하면 이렇습니다. 100명이 한 줄로 서서 메모를 전달합니다. 각 사람은 자기 메모를 쓴 뒤, 앞 사람에게 받은 메모 뭉치 위에 그냥 올려놓습니다. 중요한 메모든, 사소한 메모든 구분 없이 똑같이 쌓입니다. 100번째 사람이 받는 메모 뭉치는 너무 두꺼워져서 처음의 중요한 메모가 맨 아래 묻혀버립니다.
이것이 Kimi 팀이 발견한 문제입니다. 논문에 따르면, 기존 방식은 층이 깊어질수록 초기 층의 기여가 희석되고, 숨겨진 상태의 크기가 통제 없이 계속 커지는 현상이 발생합니다.
해법: 중요한 정보만 골라 읽는 Attention Residuals
Kimi 팀이 제안한 Attention Residuals(AttnRes)는 발상을 바꿨습니다. 메모를 그냥 쌓는 대신, 각 층이 이전 층들의 결과물을 훑어보고 중요한 것에만 집중합니다. AI가 "지금 내 질문에는 3번째 층의 문맥 분석이 가장 중요하니까, 그걸 더 크게 반영하겠다"고 스스로 판단하는 것입니다.
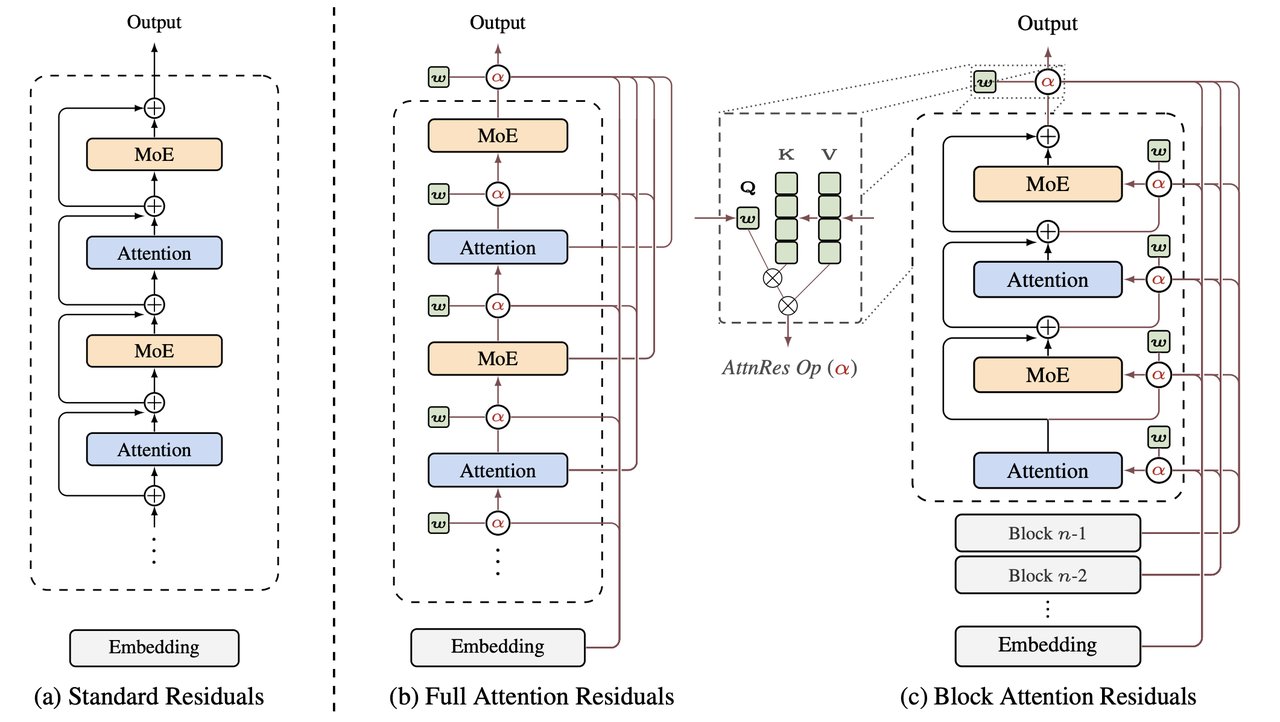
위 그림에서 왼쪽 (a) Standard Residuals는 기존 방식 — 모든 층의 결과를 균일하게 더합니다. 오른쪽 (c) Block Attention Residuals는 새 방식 — 블록 단위로 나누어 이전 블록들의 정보를 선택적으로 가져옵니다.
실용적인 변형인 Block AttnRes는 층을 8개 블록으로 묶어 메모리 부담을 줄이면서도 거의 같은 성능을 보여줍니다. 기존 AI 코드를 크게 수정하지 않고도 적용할 수 있는 드롭인 교체(기존 부품을 빼고 새 부품을 끼우듯 교체하는 방식) 방식입니다.
Attention Residuals 벤치마크 성능 비교
480억 개 매개변수를 가진 Kimi Linear 모델에서 1.4조 개 데이터로 테스트한 결과입니다.
복잡한 과학·수학 문제를 풀어내는 능력이 크게 향상됐습니다.
AI가 사람이 작성할 법한 코드를 만들어내는 정확도가 개선됐습니다.
일반 지식 (MMLU): 73.5점 → 74.6점 (+1.1점)
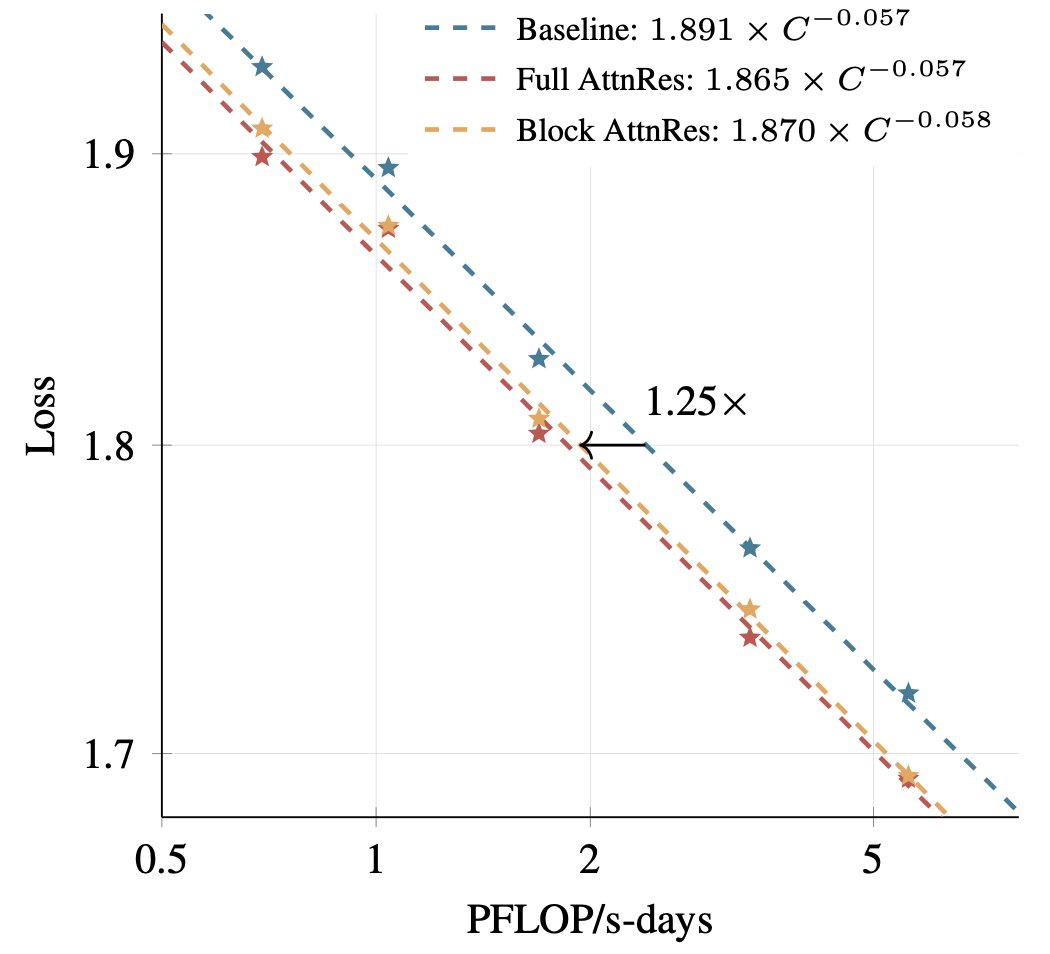
위 그래프가 핵심입니다. 가로축은 투입한 컴퓨팅 자원, 세로축은 AI의 오류율(낮을수록 좋음)입니다. 빨간선(Full AttnRes)과 주황선(Block AttnRes)이 파란선(기존 방식)보다 항상 아래에 위치합니다. 같은 컴퓨팅을 투입해도 AttnRes가 더 좋은 결과를 냅니다. 반대로 말하면, 같은 결과를 내려면 기존 방식은 AttnRes보다 1.25배(25%) 더 많은 컴퓨팅이 필요합니다.
AI 서비스 비용 절감 효과와 전망
OpenAI, Anthropic, Google 같은 AI 기업들이 이 기술을 채택하면, AI를 학습시키고 운영하는 데 드는 전기와 GPU 비용이 줄어들 수 있습니다. ChatGPT를 운영하는 데만 하루에 수십억 원이 든다고 알려져 있습니다. 25% 효율 개선은 기업에게 연간 수천억 원 규모의 절감 효과가 될 수 있습니다.
물론 AI 구독료가 바로 25% 내려가지는 않겠지만, 장기적으로 같은 가격에 더 똑똑한 AI 서비스를 제공하는 방향으로 작용할 가능성이 높습니다. 또는 같은 비용으로 더 큰 모델을 훈련시켜, AI의 성능 자체가 한 단계 올라갈 수도 있습니다. 이런 효율 개선이 쌓이면 에이전틱 AI처럼 여러 AI가 협력하는 고급 시스템도 더 현실적인 비용으로 구현할 수 있게 됩니다.
MoonshotAI와 Kimi — 중국 AI 스타트업의 Transformer 연구
MoonshotAI는 중국의 AI 스타트업으로, Kimi라는 AI 챗봇 서비스를 운영합니다. ChatGPT의 경쟁자 중 하나로, 최신 모델 K2.5와 함께 코딩 전용 모듈(Kimi Code), 멀티 에이전트 시스템(Agent Swarm) 등을 서비스하고 있습니다.
이번 논문에는 36명의 연구원이 참여했으며, 2026년 3월 16일 arXiv에 공개된 이후 깃허브에서 2,200개 이상의 스타를 받았습니다. Transformer 구조 개선이라는 기초 연구 분야에서 이 정도 관심은 이례적입니다.
AI 개발자를 위한 드롭인 적용 방법
이 기술의 가장 큰 장점은 드롭인 교체가 가능하다는 점입니다. 기존 Transformer 기반 AI 모델에 코드 몇 줄만 바꾸면 적용할 수 있습니다. 대규모 재훈련이나 아키텍처 재설계가 필요 없습니다.
AI 모델을 직접 훈련하거나 연구하는 분이라면, 깃허브 저장소에서 PyTorch 스타일의 의사 코드와 논문 PDF를 확인할 수 있습니다. AI 개발 도구와 API 연동 방법이 궁금하다면 학습 가이드도 참고해 보세요.
# Attention Residuals 논문 및 구현 코드 확인
git clone https://github.com/MoonshotAI/Attention-Residuals.git
# 논문 PDF 열기
open Attention_Residuals.pdfTransformer가 등장한 지 9년이 지났지만, 이렇게 기본적인 구조에서 25%나 되는 효율 개선이 가능했다는 점은 놀랍습니다. AI의 핵심 엔진에도 아직 개선할 여지가 많이 남아 있다는 뜻이기도 합니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기