내가 쓰는 AI를 학습시키는 데 필요한 데이터가 10분의 1로 줄었다 — 깃허브 4900 스타 NanoGPT 프로젝트의 돌파구
AI 학습에 필요한 데이터를 10분의 1로 줄이는 기법이 공개됐습니다. QLabs 연구팀이 NanoGPT 프로젝트에서 앙상블 학습과 반복 연산을 결합해 달성한 결과이며, 1년 내 100배 효율화를 목표로 합니다.
AI를 학습시키려면 엄청난 양의 데이터가 필요합니다. ChatGPT 같은 대형 모델은 인터넷의 텍스트 수십억 건을 읽고 배웠습니다. 그런데 같은 성능을 10분의 1 데이터만으로 달성하는 방법이 발견됐습니다. 해커뉴스에서 94표를 받으며 주목받은 이 연구는, AI 산업의 가장 큰 고민 중 하나인 '데이터 부족 문제'에 대한 실마리를 제시합니다.
• 18억 개 파라미터 AI 모델 8개를 조합해, 1억 개 토큰(단어 단위)만으로 원래 10억 개가 필요한 성능을 달성
• 기존 대비 10배 데이터 효율 — 같은 결과를 훨씬 적은 학습 자료로 도달
• 1년 안에 100배 효율화를 목표 — AI 학습 비용이 획기적으로 줄어들 가능성
왜 데이터 효율이 중요한가
AI 업계에는 '데이터 벽(data wall)'이라는 우려가 있습니다. 컴퓨터 성능(연산력)은 계속 좋아지는데, AI를 학습시킬 새로운 데이터는 점점 부족해지고 있다는 것입니다. 인터넷에 있는 양질의 텍스트 데이터는 이미 대부분 사용됐고, 새로운 데이터를 확보하는 것은 비용과 저작권 문제 때문에 갈수록 어려워지고 있습니다.
이번 연구의 핵심 통찰은 간단합니다: "데이터가 부족하면, 같은 데이터를 더 효율적으로 학습하면 된다." 연산력은 넘치는데 데이터가 부족한 상황(연구팀이 'Infinite Compute'라고 부르는 환경)에서, 데이터 한 건 한 건을 최대한 깊이 학습하는 기법을 개발한 것입니다.
어떻게 10배 효율을 달성했나
이 연구는 안드레이 카파시(테슬라 AI 총괄 출신)가 만든 NanoGPT 프로젝트를 기반으로 합니다. 깃허브 스타 4,900개를 기록한 이 프로젝트는 AI 학습 속도를 경쟁하는 '스피드런'으로 유명한데, QLabs 연구팀은 여기에 '슬로우런'이라는 새로운 트랙을 추가했습니다. 속도 대신 데이터 효율을 겨루는 것입니다.
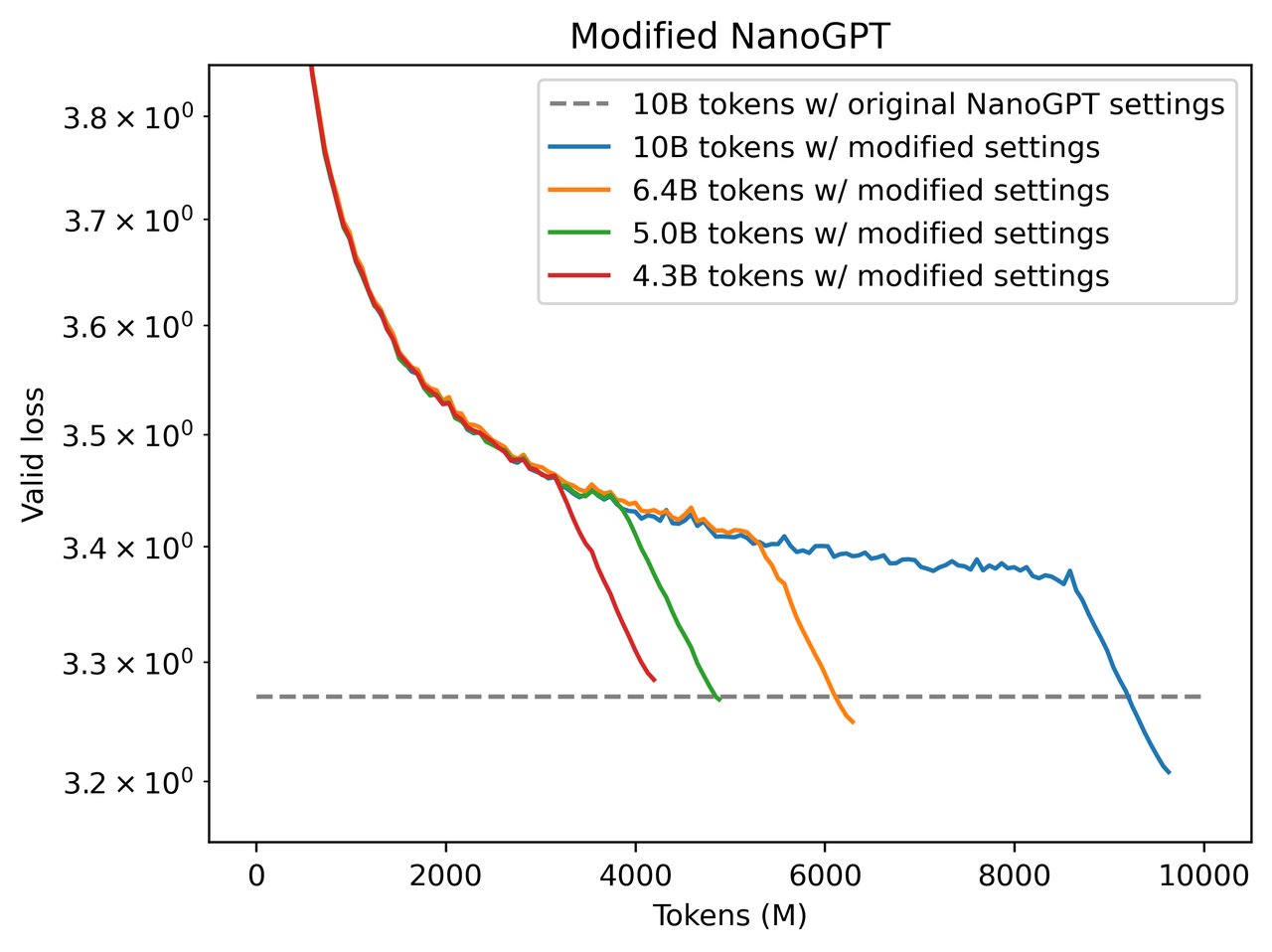
▲ 학습 곡선 비교. 수정된 방식(빨간색)은 43억 토큰만으로 기존 100억 토큰(회색 점선)과 같은 성능에 도달합니다. 출처: modded-nanogpt GitHub
연구팀이 사용한 핵심 기법 3가지를 쉽게 풀어보면 이렇습니다:
한 명의 학생이 책을 읽는 것보다, 여덟 명이 각자 읽고 답을 모으면 더 정확합니다. 연구팀은 18억 개 파라미터(AI의 뇌세포에 해당) 모델 8개를 각각 따로 학습시킨 뒤 답을 합쳤습니다. 개별 모델은 한계에 부딪혔지만, 8개를 합치니 데이터 효율이 8배로 뛰었습니다.
첫 번째 모델이 배운 내용을 두 번째 모델에게 전달하고, 두 번째가 배운 것을 세 번째에게 넘기는 방식입니다. 마치 선배가 후배에게 핵심 정리 노트를 물려주는 것처럼, 같은 데이터에서 점점 더 깊은 통찰을 뽑아냅니다.
AI가 데이터를 한 번 읽고 지나가는 대신, 핵심 부분을 4번 반복해서 처리합니다. 사람이 어려운 문장을 여러 번 다시 읽으면 이해가 깊어지는 것과 같은 원리입니다. 이 기법만으로 학습 성능이 의미 있게 향상됐습니다.
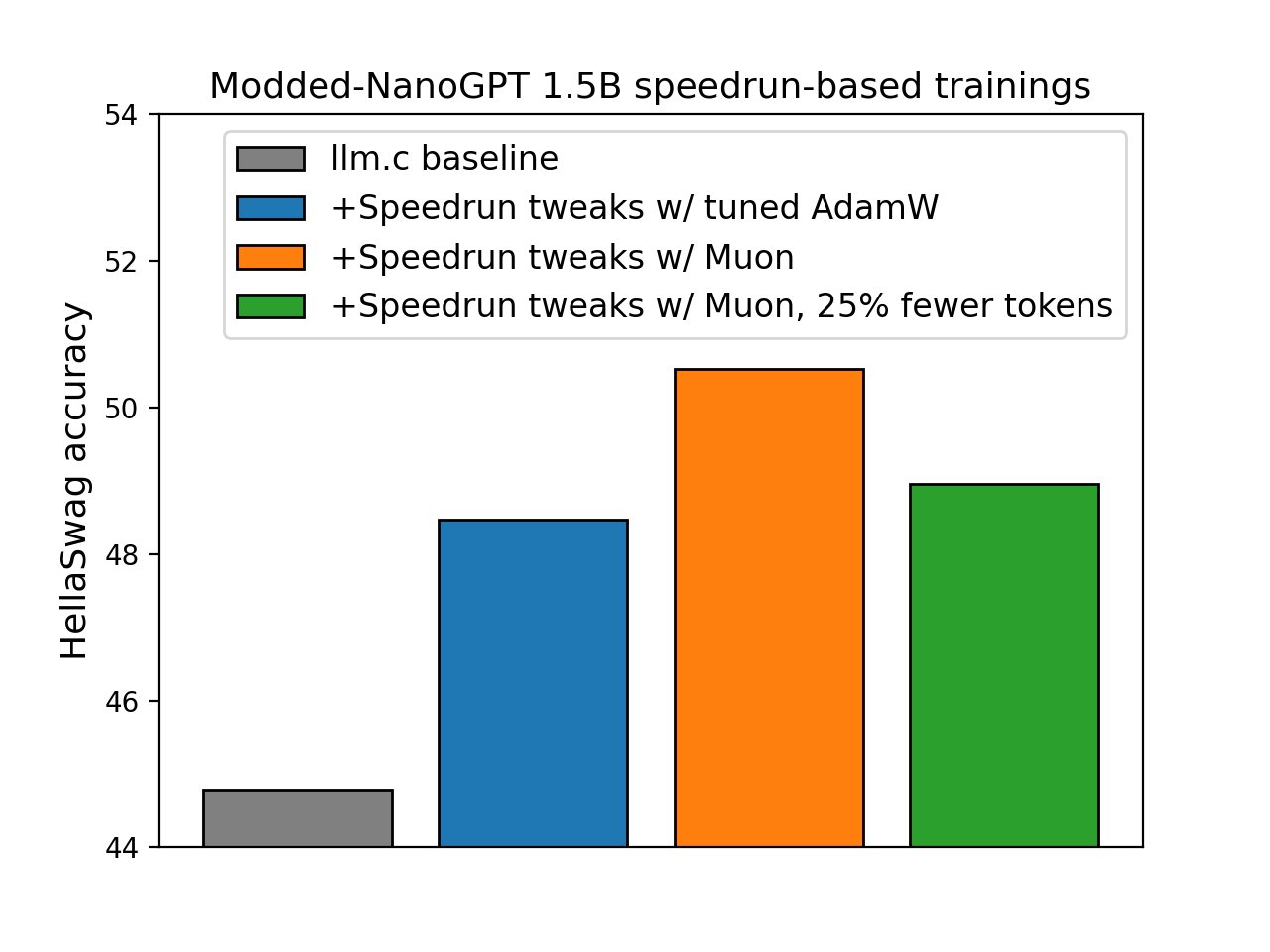
▲ 최적화 기법을 적용할수록 같은 데이터로 더 높은 정확도(HellaSwag 벤치마크)를 달성합니다. 출처: modded-nanogpt GitHub
이 연구가 내가 쓰는 AI에 미칠 영향
이 연구 결과가 실제 AI 제품에 적용되면 어떤 변화가 올까요?
첫째, AI 학습 비용이 크게 줄어듭니다. 현재 대형 AI 모델 하나를 학습시키는 데 수백억 원이 들어갑니다. 데이터를 10분의 1만 써도 된다면, 학습 시간과 비용도 대폭 줄어듭니다. 이는 결국 AI 서비스 구독료 인하로 이어질 수 있습니다.
둘째, 한국어처럼 데이터가 적은 언어의 AI가 더 똑똑해질 수 있습니다. 영어에 비해 한국어 학습 데이터는 턱없이 부족합니다. 같은 데이터로 10배 더 효율적으로 학습할 수 있다면, 한국어 AI의 품질이 영어 수준에 가까워질 가능성이 열립니다.
셋째, 소규모 기업과 연구자도 경쟁력 있는 AI를 만들 수 있습니다. 지금까지는 구글, OpenAI 같은 대기업만 충분한 데이터와 연산력을 갖고 있었습니다. 데이터 효율이 높아지면 작은 팀도 독자적인 AI를 학습시킬 수 있는 길이 열립니다.
45분에서 1분 26초로 — NanoGPT 스피드런의 역사
이번 연구가 나온 modded-nanogpt 프로젝트는 AI 학습 최적화의 살아있는 역사입니다. 2024년 5월 첫 기록은 45분이었는데, 77번의 세계 기록 갱신을 거쳐 2026년 3월 현재 1분 26초까지 단축됐습니다. 약 31배 빨라진 셈입니다.
이 프로젝트에서 검증된 기술들 — Muon 옵티마이저(AI 학습 방향을 정하는 알고리즘), Flash Attention(메모리를 절약하면서 빠르게 학습하는 기법), U-Net 스킵 연결(정보가 지름길을 타고 흐르게 하는 구조) — 은 이미 실제 AI 제품에 적용되고 있습니다.
QLabs 연구팀은 "1년 안에 100배 데이터 효율화가 가능하다"고 밝혔습니다. 이것이 실현되면, 현재 100억 건의 데이터가 필요한 AI 학습을 1억 건만으로도 해낼 수 있게 됩니다.
해커뉴스 반응 — '데이터가 아니라 알고리즘이 답이었다'
해커뉴스에서 이 연구는 94표를 받으며 활발한 토론을 이끌어냈습니다. 연구자들 사이에서는 "결국 데이터를 더 모으는 게 아니라, 같은 데이터를 더 잘 학습하는 알고리즘을 만드는 것이 핵심"이라는 공감대가 형성됐습니다. 이는 AI 업계가 그동안 '더 많은 데이터, 더 큰 모델'이라는 공식에 매달려온 것과 대비되는 방향 전환입니다.
AI 연구에 관심 있다면, QLabs의 상세 연구 노트에서 기법별 성능 향상 수치를 직접 확인할 수 있습니다. 전체 코드와 학습 로그도 깃허브에 공개되어 있어 누구나 재현해볼 수 있습니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기