AI가 짠 코드의 버그가 43% 늘었다 — 코드를 직접 읽고 검사하는 AI Canary
AI 코딩 도구가 빨라질수록 고객 장애는 43% 늘었습니다. YC W26 스타트업 Canary는 코드 변경사항을 직접 읽고, 테스트를 자동 생성·실행해 버그를 잡습니다. GPT-5.4와 Claude를 꺾은 벤치마크 결과도 공개됐습니다.
AI 코딩 도구 덕분에 개발 속도는 5~10배 빨라졌습니다. 그런데 정작 고객이 겪는 서비스 장애는 전년 대비 43% 늘었습니다. 코드를 짜는 속도는 폭발적으로 올랐지만, 그 코드가 제대로 작동하는지 검사하는 속도는 제자리걸음이었기 때문입니다.
Y Combinator 2026년 겨울 배치(W26)에서 선발된 스타트업 Canary가 이 문제에 정면으로 도전합니다. 구글과 Windsurf(AI 코딩 도구 회사)에서 일했던 엔지니어들이 만든 이 도구는, 코드 변경사항을 직접 읽고 → 어떤 기능이 영향받는지 파악하고 → 테스트를 자동으로 만들어 실행합니다.
코드를 '짜는 AI'는 많은데, '검사하는 AI'는 없었습니다
Canary의 창업자들은 문제를 이렇게 정의합니다: "코드 생성은 이미 해결된 문제입니다. 코드 검증은 아직 해결되지 않았습니다."
현실은 이렇습니다. 개발팀은 AI로 코드를 빠르게 작성하지만, 그 코드가 기존 기능을 망가뜨리지 않는지 확인하는 작업은 여전히 사람이 직접 해야 합니다. 품질 검사(QA) 팀이 아예 없는 회사도 많고, 있어도 AI가 쏟아내는 코드량을 따라가지 못합니다.
• 고객 장애 발생률: 전년 대비 43% 증가
• Canary 벤치마크 점수: 83.1점 (GPT-5.4는 80.2점, Claude Opus는 78.0점)
• 테스트 커버리지 도달 속도: 기존 수 주 → 수일 내 90% 이상
• 테스트 대상: 실제 운영 중인 Grafana, Mattermost, Cal.com, Apache Superset 등 오픈소스 프로젝트
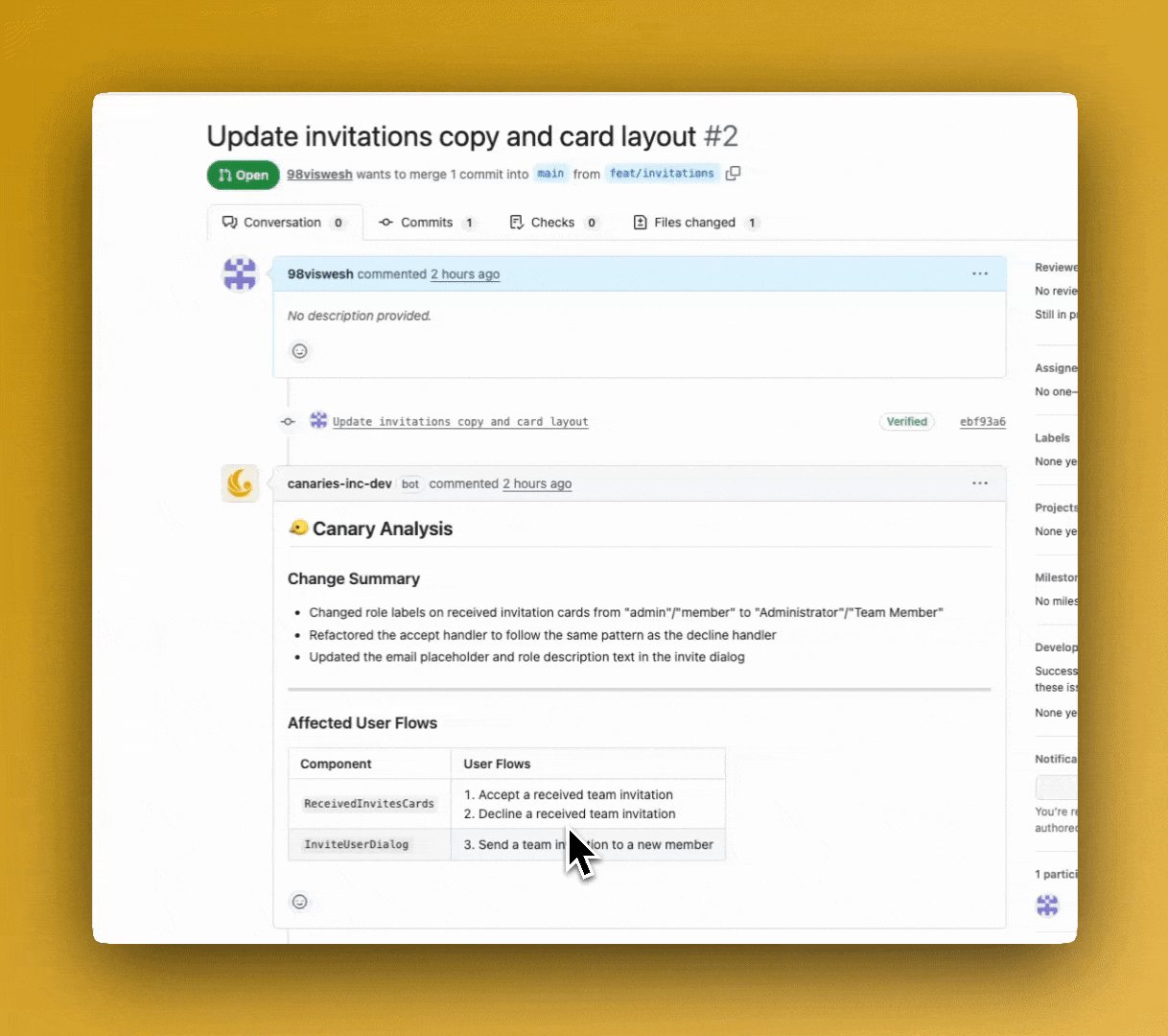
Canary는 이렇게 동작합니다
개발자가 코드를 수정해서 검토 요청(Pull Request)을 올리면, Canary가 자동으로 5단계 작업을 수행합니다.
2단계 — 변경으로 영향받는 사용자 기능(로그인, 결제, 초대 등)을 자동으로 식별합니다
3단계 — 해당 기능에 대한 테스트를 자동 생성하고, 실제 브라우저에서 병렬 실행합니다
4단계 — 테스트 결과를 PR 댓글로 남깁니다. 실패한 테스트는 영상 녹화본과 함께 보여줍니다
5단계 — 실패 항목을 클릭하면 정확히 어디서 문제가 생겼는지 세션 리플레이(화면 녹화 재생)로 확인할 수 있습니다
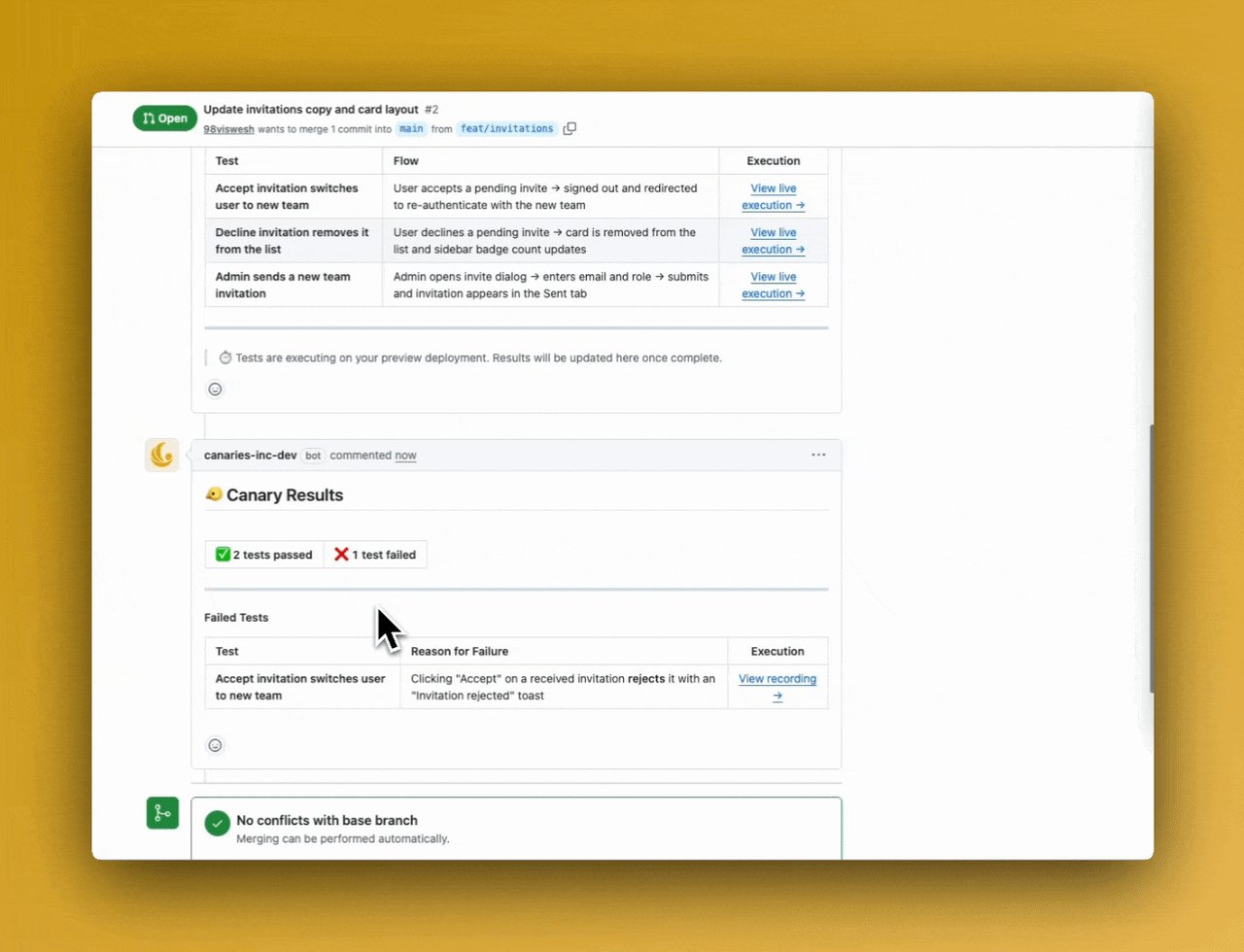
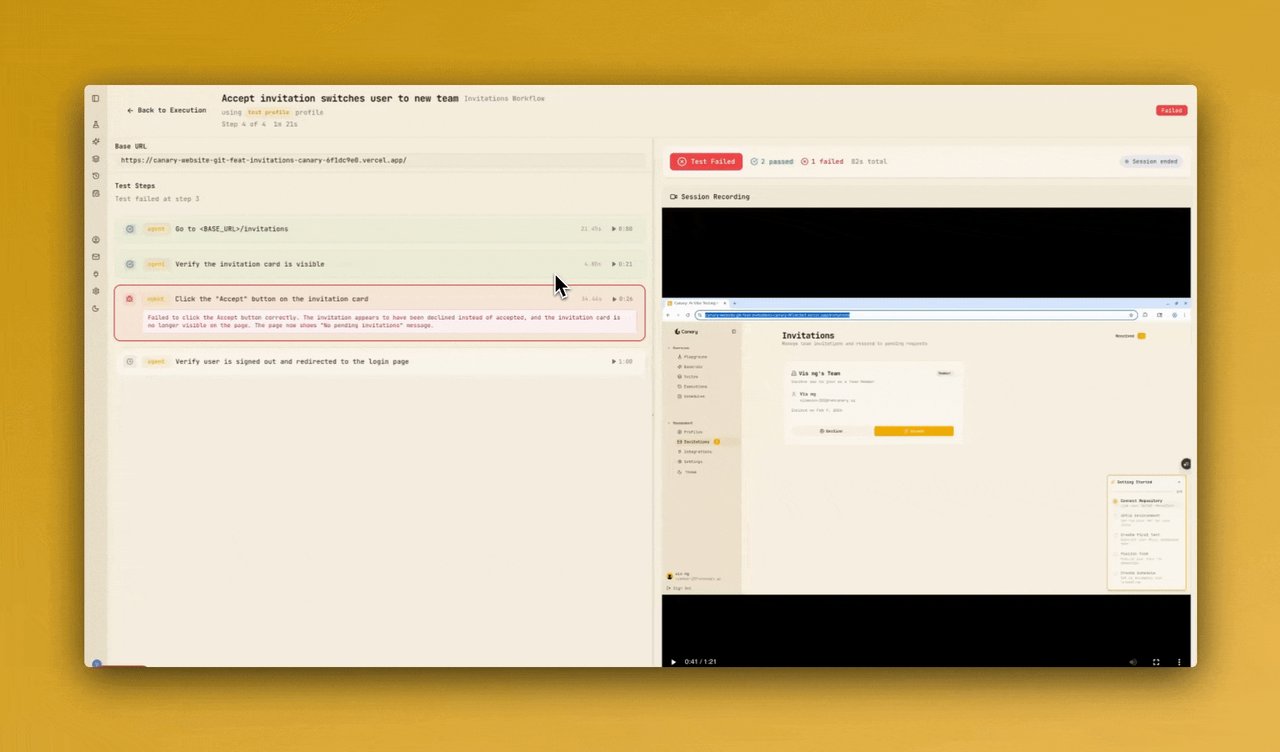
특히 인상적인 기능은 버그 재현 영상입니다. 테스트가 실패하면 Canary가 브라우저에서 직접 실행한 과정을 영상으로 녹화해 보여줍니다. "어디서 왜 깨졌는지" 추측할 필요 없이, 영상을 보면 바로 알 수 있습니다.
GPT-5.4와 Claude를 이긴 벤치마크 결과
Canary 팀은 QA-Bench v0이라는 자체 벤치마크를 만들어, AI가 코드 변경사항을 얼마나 정확하게 검증하는지 측정했습니다. 실제 운영 중인 오픈소스 프로젝트(Grafana, Mattermost, Cal.com, Apache Superset)의 35개 Pull Request를 대상으로 테스트했습니다.
| AI 모델 | 관련성 | 커버리지 | 명확성 | 종합 점수 |
|---|---|---|---|---|
| Canary | 87.4 | 84.5 | 77.4 | 83.1 |
| GPT-5.4 | 82.8 | 73.2 | 84.5 | 80.2 |
| Claude Opus 4.6 | 83.2 | 66.3 | 84.5 | 78.0 |
| Sonnet 4.6 | 77.2 | 58.8 | 83.7 | 73.2 |
가장 눈에 띄는 차이는 커버리지(검사 범위) 점수입니다. Canary는 84.5점을 기록한 반면, GPT-5.4는 73.2점, Claude Opus는 66.3점에 그쳤습니다. 커버리지란 "코드 변경으로 영향받는 모든 기능을 빠짐없이 검사했는가"를 측정하는 지표입니다.
Canary 팀은 이 차이를 아키텍처의 차이로 설명합니다. GPT나 Claude는 코드를 한 번에 읽고 테스트를 생성하지만, Canary는 코드 분석 → 영향 범위 파악 → 테스트 생성의 다단계 과정을 거칩니다. 이 과정에서 "이 로그인 코드가 바뀌면 초대 수락 기능도 깨질 수 있다"는 식의 2차 영향을 더 잘 잡아냅니다.
다만 공정하게 볼 점도 있습니다. 이 벤치마크는 Canary 팀이 직접 만들었고, 대상 PR이 35개로 적은 편입니다. 심판 역할을 한 것도 AI(Claude Opus)였기 때문에, 외부 검증이 추가로 필요합니다. 팀도 이 한계를 인정하고, V1에서는 사람이 직접 평가하는 방식을 도입할 계획이라고 밝혔습니다.
개발자와 QA 담당자에게 의미 있는 이유
개발자라면 — 코드를 수정할 때마다 "혹시 다른 기능을 망가뜨린 건 아닐까" 걱정하면서 수동으로 테스트를 작성하는 시간을 줄일 수 있습니다. 특히 AI 코딩 도구(Cursor, Claude Code 등)로 대량의 코드를 빠르게 생성하는 팀이라면, 검증 병목을 해소하는 데 도움이 됩니다.
QA 담당자라면 — 반복적인 회귀 테스트(이전에 잘 되던 기능이 여전히 작동하는지 확인하는 테스트)를 자동화할 수 있습니다. Canary가 생성한 테스트를 한 번 검토한 뒤 회귀 테스트 목록에 추가하면, 이후 모든 코드 변경 시 자동으로 실행됩니다.
팀 리더라면 — "테스트를 더 작성해야 한다"는 것을 알면서도 일정 때문에 미루던 상황에서, AI가 테스트 작성 부담을 떠안아주는 셈입니다. Canary 측은 수 주 걸리던 90% 테스트 커버리지 달성을 수일 내로 단축했다고 주장합니다.
아직 초기 단계 — 알아둘 제약 사항
Canary는 현재 얼리 액세스 단계입니다. 아직 누구나 바로 사용할 수 있는 것은 아니고, 공식 사이트에서 신청해야 합니다.
현재 확인된 제약 사항은 다음과 같습니다.
• 백엔드 테스트 미지원 — 현재는 사용자가 브라우저에서 보는 화면 기준으로만 테스트합니다
• 가격 미공개 — 정식 출시 전이라 요금 체계가 아직 발표되지 않았습니다
• 벤치마크 자체 제작 — 독립적인 제3자 검증은 아직 이뤄지지 않았습니다
Hacker News 커뮤니티에서도 "PR마다 알림이 너무 많으면 피로해질 수 있다", "생성된 테스트가 PR이 닫힌 뒤에도 안정적으로 유지되는지가 관건"이라는 현실적인 피드백이 나왔습니다. 팀은 이런 의견을 반영해 알림을 하나로 합치고, 백엔드 테스트 지원도 추가할 예정이라고 답했습니다.
AI 코딩 시대의 다음 질문: "누가 검사하나?"
AI가 코드를 짜는 시대에, "그 코드를 누가 검증하느냐"는 점점 더 중요한 질문이 되고 있습니다. Canary는 "AI가 짠 코드를 AI가 검증한다"는 방향으로 답을 제시합니다.
같은 고민을 하는 움직임이 곳곳에서 보입니다. 지난주에는 해커뉴스에서 "AI가 코드를 바꾸는 방식에 의도적이어야 한다"는 글이 88점을 받으며 화제가 됐고, 구글 엔지니어가 경고한 이해력 부채(AI가 작성한 코드를 아무도 이해하지 못하는 상황)도 큰 관심을 받았습니다.
Canary가 이 문제의 완전한 답이 될지는 시간이 더 필요합니다. 하지만 "코드 생성은 해결됐고, 이제 코드 검증이 다음 전장"이라는 메시지는 명확합니다. AI 코딩 도구를 적극 활용하는 팀이라면, 검증 자동화도 함께 고민할 시점입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기