200만 원짜리 AI 전용 기기의 실체 — 엔지니어가 분해해보니 40만 원 부품이었습니다
TiinyAI Pocket Lab이 '120B 모델을 초당 20토큰'이라 광고했지만, 실제 활성 파라미터는 51억 개뿐이고 메모리 병목으로 실사용 속도는 73% 느려집니다. 한 엔지니어의 역분석 결과를 정리했습니다.
'손바닥 위의 AI 슈퍼컴퓨터'라는 광고 문구로 화제를 모은 TiinyAI Pocket Lab. USB-C로 노트북에 연결하면 인터넷 없이 AI를 돌릴 수 있다는 이 기기의 가격은 1,399달러(약 195만 원)입니다. 그런데 한 엔지니어가 마케팅 사진과 공개 영상만으로 내부 구조를 역분석(리버스 엔지니어링)한 결과, 광고와 실제 성능 사이에 심각한 괴리가 발견됐습니다.

'1200억 파라미터'의 진실 — 실제로 일하는 건 51억 개뿐
TiinyAI는 이 기기가 GPT-OSS-120B라는 1200억 파라미터 모델을 초당 20토큰으로 돌린다고 광고합니다. 숫자만 보면 ChatGPT급 AI를 주머니에 넣고 다니는 것처럼 보입니다.
하지만 핵심을 들여다보면 이야기가 달라집니다. 이 모델은 MoE(Mixture of Experts) 방식입니다. 쉽게 말해, 1200억 개의 '뇌세포' 전체가 동시에 일하는 게 아니라, 질문 하나당 51억 개만 골라서 작동합니다. 마케팅에서는 '전체 인원' 1200억을 강조하지만, 실제로 한 번에 일하는 '당번'은 51억뿐인 셈입니다.
51억 파라미터짜리 AI 모델이라면? 요즘 스마트폰에서도 돌아가는 수준입니다.
메모리가 둘로 쪼개진 설계 — 12배 느린 병목
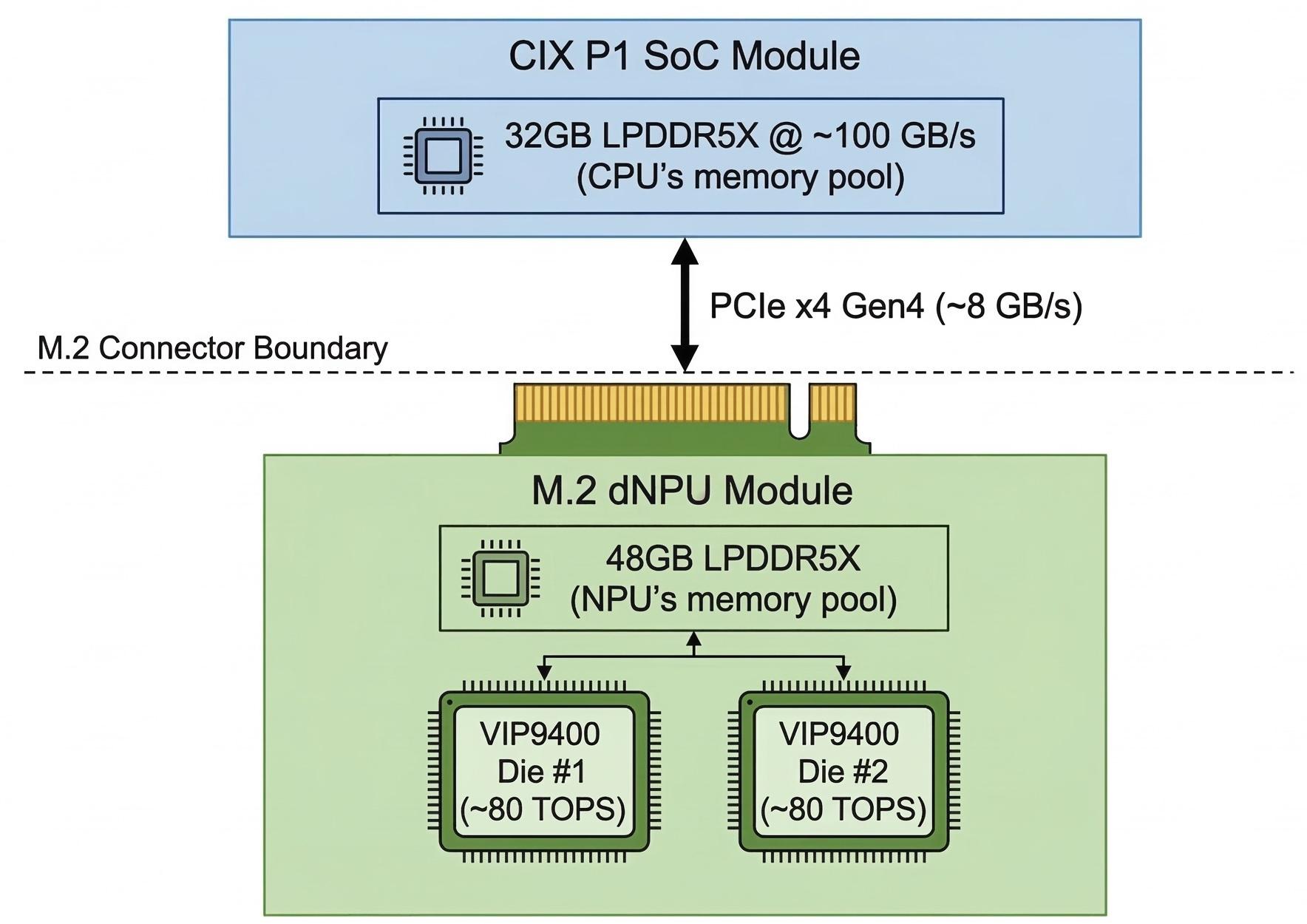
이 기기의 가장 큰 문제는 메모리 구조입니다. 총 80GB 메모리를 광고하지만, 실제로는 CPU 쪽 32GB와 AI 전용 칩(NPU) 쪽 48GB로 나뉘어 있습니다.
각각의 메모리는 초당 100GB 속도로 빠르게 작동합니다. 문제는 이 두 메모리를 연결하는 통로(PCIe Gen4 x4)가 초당 8GB밖에 안 된다는 것입니다. 빠른 고속도로 두 개를 좁은 골목길 하나로 연결해놓은 격입니다.
광고 속도 vs 실제 속도 — 대화가 길어지면 73% 느려진다
엔지니어가 유튜브 리뷰 영상들의 실측 데이터를 분석한 결과입니다.
| 상황 | 속도 | 광고 대비 |
|---|---|---|
| 짧은 질문 (256토큰) | 16.85 tok/s | 이미 광고보다 느림 |
| 일반 대화 (8K토큰) | 12.04 tok/s | 40% 느림 |
| 긴 문서 분석 (32K토큰) | 6.04 tok/s | 64% 느림 |
| 보고서 작성 (64K토큰) | 4.47 tok/s | 73% 느림 |
특히 64K 토큰(A4 약 50페이지 분량) 처리 시 첫 응답까지 28분이 걸렸습니다. 실무에서 AI 코딩 도우미나 문서 분석에 쓰려면 최소 8K~32K 토큰이 필요한데, 바로 그 구간에서 성능이 무너집니다.
내부를 들여다보니 — 30만~40만 원짜리 부품 조합

역분석 결과 드러난 핵심 부품은 다음과 같습니다.
AI 전용 칩(NPU): VeriSilicon VIP9400 2개 — 각각 80TOPS 성능의 범용 칩
메모리: 32GB + 48GB LPDDR5X (둘로 나뉨)
저장장치: 1TB NVMe SSD
엔지니어의 결론은 명확합니다. 시중에서 52만 원(400달러)에 살 수 있는 RTX 4060 Ti 그래픽카드가 같은 종류의 AI 모델을 7배 더 빠르게 돌리고, 10만 토큰 이상의 긴 대화도 문제없이 처리합니다.
회사 실체도 불투명하다
기술적 문제 외에도 기업 투명성에 대한 우려가 제기됐습니다.
직원 4명 — 링크드인 검색 결과 확인된 인원이 4명뿐이며, 대부분 홍콩 기반
연구 출처 논란 — 핵심 기술 PowerInfer는 상하이자오퉁대학교가 2023년 12월에 발표한 논문인데, TiinyAI는 2024년 1월 설립 후 이를 자사 기술로 표기
원래 GitHub 저장소가 TiinyAI 계정으로 리다이렉트됨
구매를 고민 중이라면 꼭 확인할 것
이 기기는 2026년 8월 배송 예정이며 현재 선주문을 받고 있습니다. 구매 전 확인해야 할 핵심 사항을 정리합니다.
1. '1200억 파라미터'에 속지 마세요 — 실제 작동하는 파라미터는 51억 개입니다. 요즘 무료 AI 모델 중에서도 이 정도 규모는 흔합니다.
2. 긴 대화에는 부적합합니다 — 코딩 도우미, 문서 분석, RAG(자료를 검색해서 답하는 방식) 등 실무 용도에서 속도가 급격히 떨어집니다.
3. 더 싼 대안이 있습니다 — RTX 4060 Ti(약 52만 원)가 7배 빠르고, Ollama 같은 무료 소프트웨어로 같은 일을 할 수 있습니다.
4. 회사 정보를 확인하세요 — 경영진 이름, 연구 출처, 제조 역량에 대해 투명하게 공개하지 않는 점은 선주문 리스크입니다.
AI 하드웨어 시장의 교훈
'인터넷 없이 내 컴퓨터에서 AI를 돌리고 싶다'는 수요는 분명히 있고, 점점 커지고 있습니다. 하지만 그 수요를 노리는 제품 중에는 마케팅과 실제 성능의 간극이 큰 것들이 있습니다.
이번 역분석은 AI 하드웨어를 구매할 때 어떤 질문을 해야 하는지 알려줍니다. '몇억 파라미터'보다 '활성 파라미터가 몇 개인지', '메모리가 몇 GB인지'보다 '메모리 간 통신 속도가 얼마인지', '초당 몇 토큰인지'보다 '내가 실제로 쓸 분량에서 몇 토큰인지'를 물어야 합니다.
원문 역분석 전문은 bay41.com에서 확인할 수 있습니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기