내 PDF를 AI가 완벽히 읽는다 — 표·수식·이미지까지 정확도 1위, 한국 기업의 오픈소스 도구
한컴이 만든 오픈소스 PDF 파서 OpenDataLoader가 200개 문서 벤치마크에서 정확도 0.91로 1위를 기록했습니다. 페이지당 0.05초 처리, 표 정확도 93%, Python·Node.js·Java 지원으로 AI 워크플로우에 바로 연결됩니다.
PDF 문서를 AI에게 읽히려고 하면 표가 깨지고, 수식이 날아가고, 읽는 순서가 뒤죽박죽이 되는 경험, 한 번쯤 해보셨을 겁니다. ChatGPT나 Claude에게 PDF를 던져도 정확한 답을 받기 어려운 이유가 바로 이것입니다 — AI가 PDF를 제대로 읽지 못하기 때문입니다.
한국의 한컴(Hancom)이 이 문제를 정면으로 풀었습니다. OpenDataLoader PDF는 PDF 문서를 AI가 이해할 수 있는 형태로 변환해주는 오픈소스 도구인데, 200개 실제 PDF를 대상으로 한 벤치마크에서 정확도 0.91로 1위를 차지했습니다. 깃허브 스타는 하루 만에 1,400개가 늘어 총 4,600개를 돌파했습니다.
기존 도구들은 왜 PDF를 제대로 못 읽을까
PDF는 사람이 읽기 좋게 만들어진 형식이지, 기계가 이해하기 좋은 형식이 아닙니다. 텍스트가 좌표별로 흩어져 있고, 표는 그림처럼 저장되어 있고, 수식은 특수 기호 조합으로 들어가 있습니다. 기존의 PDF 파싱 도구들 — PyMuPDF, Marker, MinerU 같은 것들 — 은 이런 복잡한 구조를 완벽히 해석하지 못했습니다.
특히 표(table) 추출이 가장 큰 약점이었습니다. 테두리 없는 표, 셀이 합쳐진 복잡한 표는 대부분 깨졌습니다.
벤치마크 결과 — 7개 도구 중 종합 1위
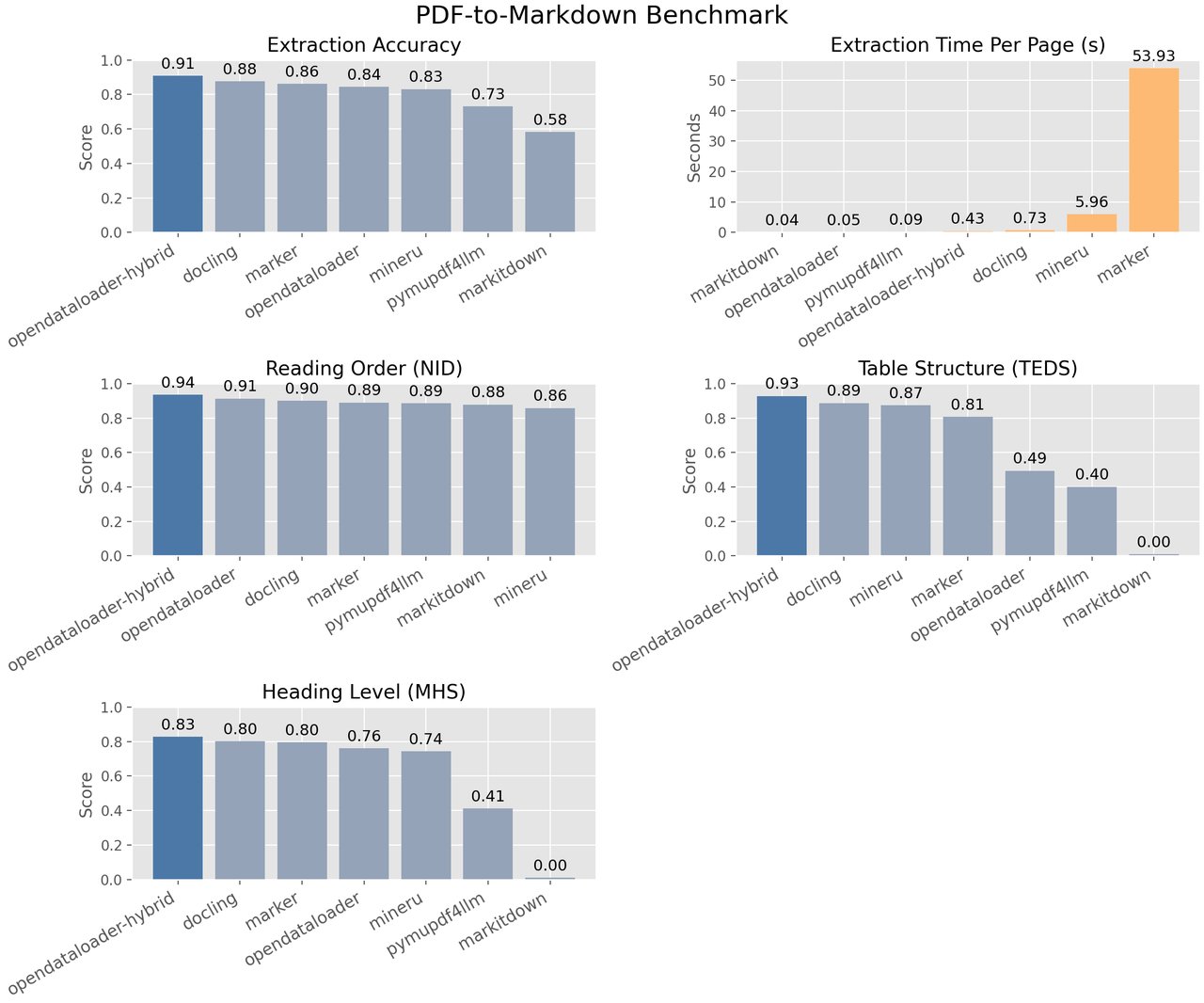
OpenDataLoader 팀은 200개 실제 PDF(학술 논문, 다단 레이아웃, 보고서 등)를 대상으로 7개 도구를 비교 테스트했습니다. 측정 항목은 세 가지입니다.
종합 정확도 (높을수록 좋음)
1위 — OpenDataLoader Hybrid: 0.91
2위 — docling: 0.86
3위 — OpenDataLoader Local: 0.84
4위 — Marker: 0.83 (속도: 페이지당 54초)
5위 — MinerU: 0.82 (속도: 페이지당 6초)
6위 — PyMuPDF4LLM: 0.57
7위 — MarkItDown: 0.29
가장 눈에 띄는 것은 표 추출 정확도입니다. OpenDataLoader Hybrid는 0.93을 기록해 2위 docling(0.89)과 3위 MinerU(0.87)를 크게 앞섰습니다. 회사 보고서나 학술 논문에서 표 데이터를 뽑아야 하는 분들에게 결정적인 차이입니다.
두 가지 모드 — 빠르게 또는 정확하게
OpenDataLoader는 상황에 따라 두 가지 모드를 선택할 수 있습니다.
Fast 모드 (로컬 처리)
페이지당 0.05초 — 인터넷 연결 없이 내 컴퓨터에서만 처리합니다. 정확도 0.84. 간단한 문서라면 이것만으로 충분합니다.
Hybrid 모드 (AI 보조)
페이지당 0.43초 — 복잡한 페이지만 AI에게 보내고, 간단한 페이지는 로컬에서 처리합니다. 정확도 0.91. 복잡한 표와 스캔 문서에 강합니다.
비교하면, Marker는 페이지당 54초가 걸립니다. OpenDataLoader Fast 모드는 Marker보다 약 1,000배 빠릅니다.
AI가 PDF를 읽을 때 실제로 이렇게 분석합니다
아래 이미지는 OpenDataLoader가 학술 논문 PDF를 분석한 결과입니다. 제목, 본문, 이미지, 참고문헌 등 각 요소를 색상별로 구분해서 추출합니다.

추출 결과는 5가지 형식으로 내보낼 수 있습니다 — JSON(위치 좌표 포함), Markdown(ChatGPT·Claude에 바로 붙여넣기 가능), HTML, 주석이 달린 PDF, 일반 텍스트. 특히 JSON 형식에는 모든 요소의 위치 좌표가 포함되어 있어서, AI가 "이 숫자는 어디서 나온 거야?"라는 질문에 원본 위치까지 짚어줄 수 있습니다.
이런 분들에게 유용합니다
사무직·연구자 — 수십 페이지 보고서에서 표와 수치를 뽑아 AI에게 분석시킬 때. Markdown으로 변환하면 ChatGPT나 Claude가 바로 이해합니다.
개발자 — RAG(AI가 문서를 검색해서 답하는 시스템) 파이프라인에 바로 연결 가능합니다. LangChain과 통합되어 있고, 프롬프트 인젝션(AI를 속이려는 악의적 명령) 필터링도 내장되어 있습니다.
스캔 문서가 많은 조직 — 80개 이상 언어의 OCR(이미지에서 글자를 인식하는 기술)을 지원합니다. 스캔된 옛날 문서도 AI가 읽을 수 있는 텍스트로 바꿔줍니다.
설치 방법 — 3줄이면 끝
Python, Node.js, Java 세 가지 언어를 모두 지원합니다. 가장 간단한 Python 설치법입니다.
# 기본 설치 (로컬 처리만)
pip install -U opendataloader-pdf
# AI 보조 모드까지 사용하려면
pip install -U "opendataloader-pdf[hybrid]"
# PDF를 마크다운으로 변환
from opendataloader_pdf import OpenDataLoader
result = OpenDataLoader.parse("내문서.pdf")
print(result.to_markdown())Node.js 사용자는 npm install @opendataloader/pdf, Java 사용자는 Maven Central에서 바로 가져올 수 있습니다. Java 11 이상이 설치되어 있어야 합니다.
한컴이 왜 이런 도구를 만들었을까
OpenDataLoader는 한국 소프트웨어 기업 한컴(Hancom)의 프로젝트입니다. PDF 표준화 단체인 PDF Association, 그리고 PDF 검증 도구 veraPDF를 만든 Dual Lab과 공동으로 개발했습니다.
한컴은 단순한 PDF 파싱을 넘어 PDF 접근성 자동화까지 목표로 하고 있습니다. 2026년 2분기에는 태그가 없는 PDF를 자동으로 접근성 표준(PDF/UA)에 맞게 변환하는 기능이 추가될 예정입니다. 유럽 접근성법(EAA), 미국 ADA, Section 508 등 각국 규제에 대응해야 하는 기업들에게 실질적인 해결책이 될 수 있습니다.
라이선스는 Apache 2.0으로 상업적 사용도 무료입니다. 깃허브에서 전체 소스 코드를 확인할 수 있고, 온라인 데모에서 직접 사용해볼 수도 있습니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기