내 그래픽카드 메모리를 12GB에서 127GB로 늘리는 무료 오픈소스 도구
GPU 메모리가 부족해서 AI 모델을 못 돌리던 시대가 끝났습니다. 오픈소스 도구 GreenBoost는 내 컴퓨터의 RAM과 SSD를 GPU 메모리처럼 활용해, 12GB 그래픽카드에서 32GB짜리 AI 모델을 실행할 수 있게 해줍니다. 설치법과 실전 성능까지 정리했습니다.
내 그래픽카드가 12GB인데, 32GB짜리 AI 모델을 돌리고 싶다면? 지금까지는 불가능하거나 값비싼 GPU를 새로 사야 했습니다. 오픈소스 프로젝트 NVIDIA GreenBoost는 내 컴퓨터의 RAM과 SSD를 GPU 메모리처럼 활용해, 12GB 그래픽카드의 사용 가능한 메모리를 127GB까지 확장합니다. Ollama(로컬 AI 실행 도구, 깃허브 스타 16만 5천)와 바로 연동되며, 기존 AI 프로그램을 수정하지 않아도 됩니다.
어떻게 12GB가 127GB가 되나
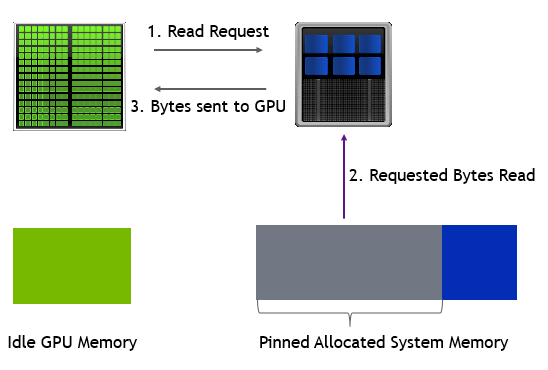
GreenBoost의 핵심은 3단계 메모리 계층 구조입니다. GPU가 필요한 데이터를 세 군데에 나눠서 저장하는 방식입니다.
이 세 단계를 합치면 12 + 51 + 64 = 127GB입니다. GreenBoost는 리눅스 커널 모듈(운영체제 핵심 부분에 설치되는 프로그램)과 CUDA 연동 장치(GPU 프로그램과 메모리 사이에서 중개 역할을 하는 소프트웨어) 두 개로 구성되어 있습니다. AI 프로그램이 GPU 메모리를 요청하면, GreenBoost가 자동으로 넘치는 부분을 RAM이나 SSD로 보냅니다.

GPU 메모리와 시스템 RAM이 하나의 가상 주소 공간을 공유하는 원리 (출처: NVIDIA Developer Blog)
실전 성능 — 느리지만 '가능'하다
솔직히 말하면, RAM 경유 속도는 GPU 전용 메모리보다 느립니다. 하지만 '아예 못 돌리는 것'과 '느리지만 돌아가는 것'은 완전히 다릅니다. 아래는 RTX 5070(12GB)에서 32GB짜리 AI 모델(glm-4.7-flash)을 돌린 실측 결과입니다.
| 실행 방식 | 응답 속도 (토큰/초) | 첫 응답까지 걸리는 시간 |
|---|---|---|
| Ollama + GreenBoost (기본) | 2~5 | 5~15초 |
| + 캐시 압축 50% | 4~8 | 3~10초 |
| ExLlamaV3 + GreenBoost 캐시 | 8~20 | 2~8초 |
| 모델 최적화 (FP8 양자화) | 10~25 | 1~5초 |
| 극한 압축 (모델 크기 8GB로 축소) | 25~60 | 0.5~2초 |
핵심 포인트: 기본 설정의 2~5 토큰/초는 실시간 대화에는 느립니다. 하지만 모델 최적화를 병행하면 25~60 토큰/초까지 올라갑니다 — 이 정도면 충분히 쾌적한 대화가 가능합니다.
GreenBoost가 사용하는 '제로카피' 방식 — GPU가 시스템 RAM에서 직접 데이터를 읽어옵니다 (출처: NVIDIA Developer Blog)
해커뉴스 개발자들의 실전 후기
이 프로젝트가 해커뉴스에 올라오자 개발자들 사이에서 의견이 갈렸습니다.
"쓸만하다" — "RTX 4070과 RAM 96GB로 Nemotron-3-Super 모델을 밤새 돌렸습니다. 퇴근 후 PC가 놀고 있을 때 AI 데이터 분류 작업을 시키기 딱 좋습니다." — bhewes
"느리다" — "극도로 느리고 실용적이지 않다고 생각합니다." — holoduke
"핵심은 '가능하냐 불가능하냐'" — "많은 머신러닝 작업을 실행할 수 있느냐, 아예 못 하느냐의 차이를 만들어줍니다." — daneel_w
정리하면, 실시간 채팅용으로는 느리지만 퇴근 후 밤새 돌리는 배치 작업(데이터 분류, 라벨링, 문서 정리)이나 모델 최적화를 병행하면 충분히 쓸 만한 수준입니다.
누가 쓰면 좋을까
설치 방법 — 리눅스 전용
현재 Ubuntu 26.04 + NVIDIA 드라이버 580.x + 커널 6.19 이상에서 동작합니다. 리눅스 환경이 필요하며, Windows와 macOS는 지원하지 않습니다.
# 프로젝트 다운로드
git clone https://gitlab.com/IsolatedOctopi/nvidia_greenboost.git
cd nvidia_greenboost
# 자동 설치 (GPU, RAM, SSD 자동 감지)
sudo ./greenboost_setup.sh full-install
# 재부팅 후 정상 동작 확인
sudo ./greenboost_setup.sh diagnose설치 스크립트가 GPU VRAM 크기, RAM 용량, SSD 여유 공간을 자동으로 감지해서 최적 설정을 잡아줍니다. 설치 후 Ollama를 실행하면 자동으로 확장된 메모리를 사용합니다.
주의할 점
- 리눅스 전용 — Windows, macOS에서는 사용할 수 없습니다
- NVIDIA GPU 전용 — AMD 그래픽카드는 지원하지 않습니다. RTX 5070(Blackwell)에서 테스트되었고, RTX 4000/3000 시리즈에서도 동작할 것으로 예상됩니다
- RAM이 충분해야 효과적 — 최소 64GB RAM 권장. 32GB RAM이면 확장 효과가 제한적입니다
- 기본 속도는 느림 — 모델 최적화(양자화) 없이 사용하면 초당 2~5단어 수준입니다. ExLlamaV3나 FP8 양자화를 함께 적용해야 실용적인 속도가 나옵니다
앞으로의 가능성
GreenBoost는 2026년 3월 14일에 처음 공개된 매우 초기 단계의 프로젝트입니다. GitLab 스타 35개로 아직 작은 커뮤니티이지만, 해커뉴스 개발자들의 반응에서 보듯 "GPU 메모리 부족"이라는 보편적인 문제를 해결한다는 점에서 성장 가능성이 있습니다.
한 사용자는 "이 프로젝트가 리눅스 메인라인 커널에 들어가면 좋겠다"고 댓글을 남기기도 했습니다. 현재는 NVIDIA GPU + 리눅스 조합에서만 사용할 수 있지만, 로컬 AI를 더 많은 사람이 쓸 수 있게 만드는 중요한 시도입니다.
비슷한 접근법으로 AMD에서는 95달러(약 13만 원)짜리 APU를 16GB GPU로 변환해서 이미지 생성 AI를 돌리는 사례도 해커뉴스에서 화제가 되었습니다. 저렴한 하드웨어로 AI를 돌리려는 움직임이 점점 커지고 있습니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기