ChatGPT를 돌리는 Transformer의 대안이 나왔다 — Mamba-3, 메모리 절반에 속도도 앞선다
ChatGPT·Claude·Gemini의 핵심 기술 Transformer에 도전하는 새 AI 구조 Mamba-3가 오픈소스로 공개됐습니다. 같은 성능에 메모리 절반, 응답 속도 6% 향상. ICLR 2026 채택.
ChatGPT, Claude, Gemini — 지금 우리가 쓰는 거의 모든 AI 서비스는 Transformer(트랜스포머)라는 하나의 핵심 기술 위에 세워져 있습니다. 2017년 구글이 발명한 이 기술은 AI 혁명의 엔진이었지만, 치명적인 약점이 하나 있습니다. 글이 길어질수록 필요한 메모리와 비용이 기하급수적으로 늘어난다는 것입니다.
3월 17일, 카네기멜론대(CMU)·프린스턴대·Together AI·Cartesia AI 공동 연구팀이 이 문제를 정면으로 겨냥한 새로운 AI 구조 Mamba-3를 오픈소스로 공개했습니다. 기존 Mamba-2 대비 내부 메모리 사용량은 절반으로 줄이면서, 응답 속도는 Transformer보다도 빨라졌습니다. 이 논문은 AI 분야 최고 학회 중 하나인 ICLR 2026에 채택됐습니다.

Transformer vs Mamba — 자동차 엔진이 바뀌는 것과 같습니다
Transformer를 자동차 엔진에 비유해 보겠습니다. 지금까지 모든 AI 자동차는 같은 엔진을 쓰고 있었습니다. 이 엔진은 매우 강력하지만 연비가 나쁩니다. 처리하는 글이 길어질수록 연료(메모리와 전기)를 급격히 더 소모합니다. 소설 한 권을 읽게 하면 소설 반 권을 읽을 때보다 4배 이상의 메모리가 필요합니다.
Mamba는 이를 근본적으로 다른 방식으로 해결합니다. SSM(상태 공간 모델, AI가 정보를 기억하고 처리하는 수학적 구조)이라는 기술을 사용해, 글이 아무리 길어져도 메모리 사용량이 일정하게 유지됩니다. 소설 한 권을 읽든 열 권을 읽든 같은 양의 메모리만 쓰는 셈입니다.
Mamba-3가 바꾼 세 가지
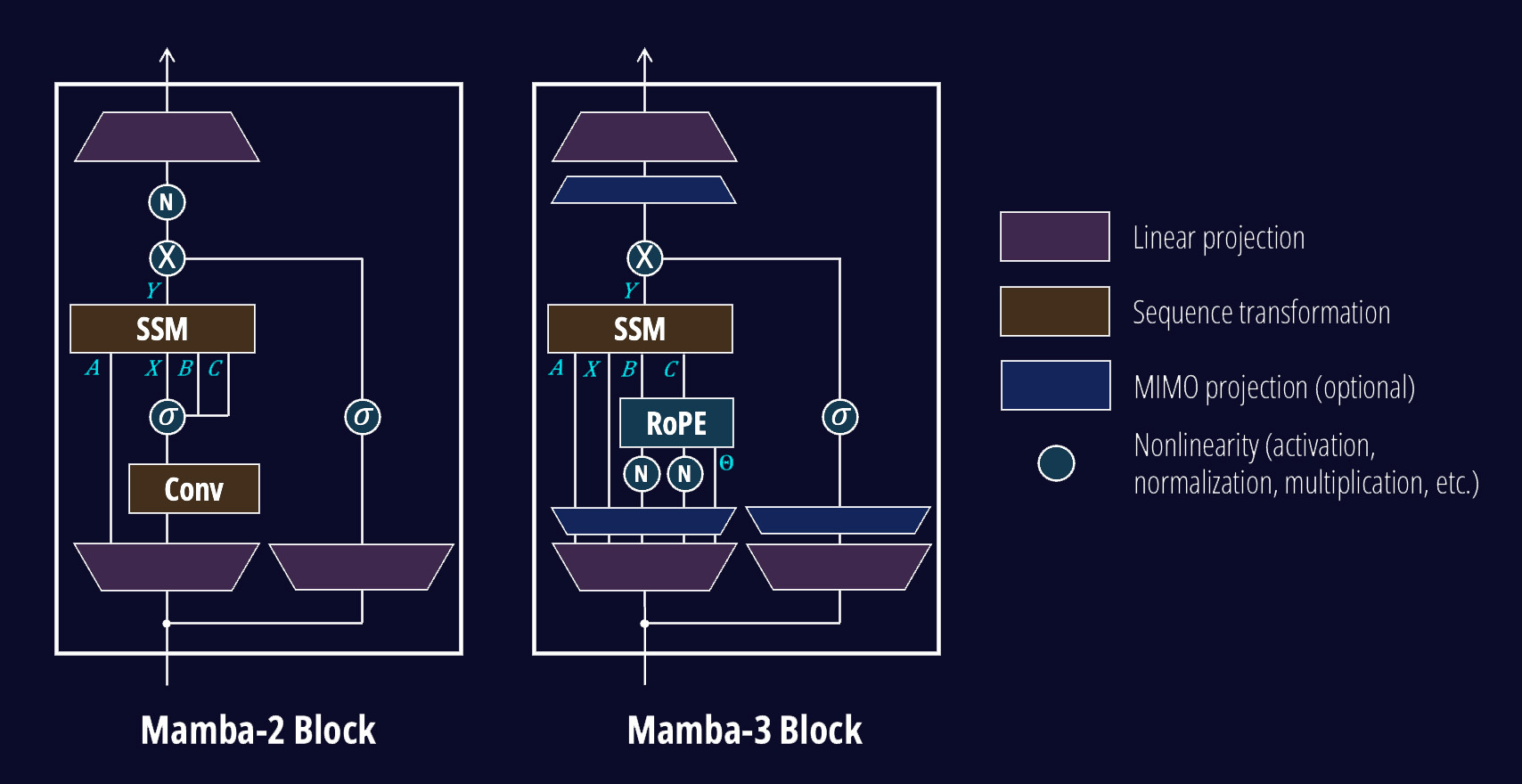
▲ Mamba-2(왼쪽)와 Mamba-3(오른쪽)의 내부 구조 비교. Mamba-3는 Conv(합성곱) 모듈을 제거하고 RoPE와 MIMO를 추가해 더 효율적으로 변했습니다. (출처: Together AI)
벤치마크 — 숫자로 확인합니다
연구팀은 NVIDIA H100 GPU에서 15억(1.5B) 파라미터 규모로 성능을 비교했습니다. 파라미터(매개변수)는 AI 모델의 크기를 나타내는 단위로, 숫자가 클수록 더 복잡한 작업을 처리할 수 있습니다.
| 모델 | 512 토큰 처리 | 4,096 토큰 처리 |
|---|---|---|
| Mamba-3 (SISO) | 4.39초 ✅ | 35.11초 ✅ |
| Mamba-2 | 4.66초 | 37.22초 |
| Llama-3.2-1B (Transformer) | 4.45초 | — |
Mamba-3 SISO는 모든 길이에서 가장 빠른 응답 속도를 기록했습니다. 512 토큰(약 400단어) 기준 Mamba-2보다 6% 빠르고, 4,096 토큰에서는 5.7% 빠릅니다. 주목할 점은 Transformer 기반 Meta의 Llama 모델보다도 빨랐다는 것입니다.
MIMO 변형은 여기에 더해 정확도를 1~1.8%포인트 추가 향상시켰습니다. 같은 속도에서 더 정확한 답을 내놓는 것입니다. 그러면서도 Mamba-2의 절반 크기의 내부 상태만 사용합니다.
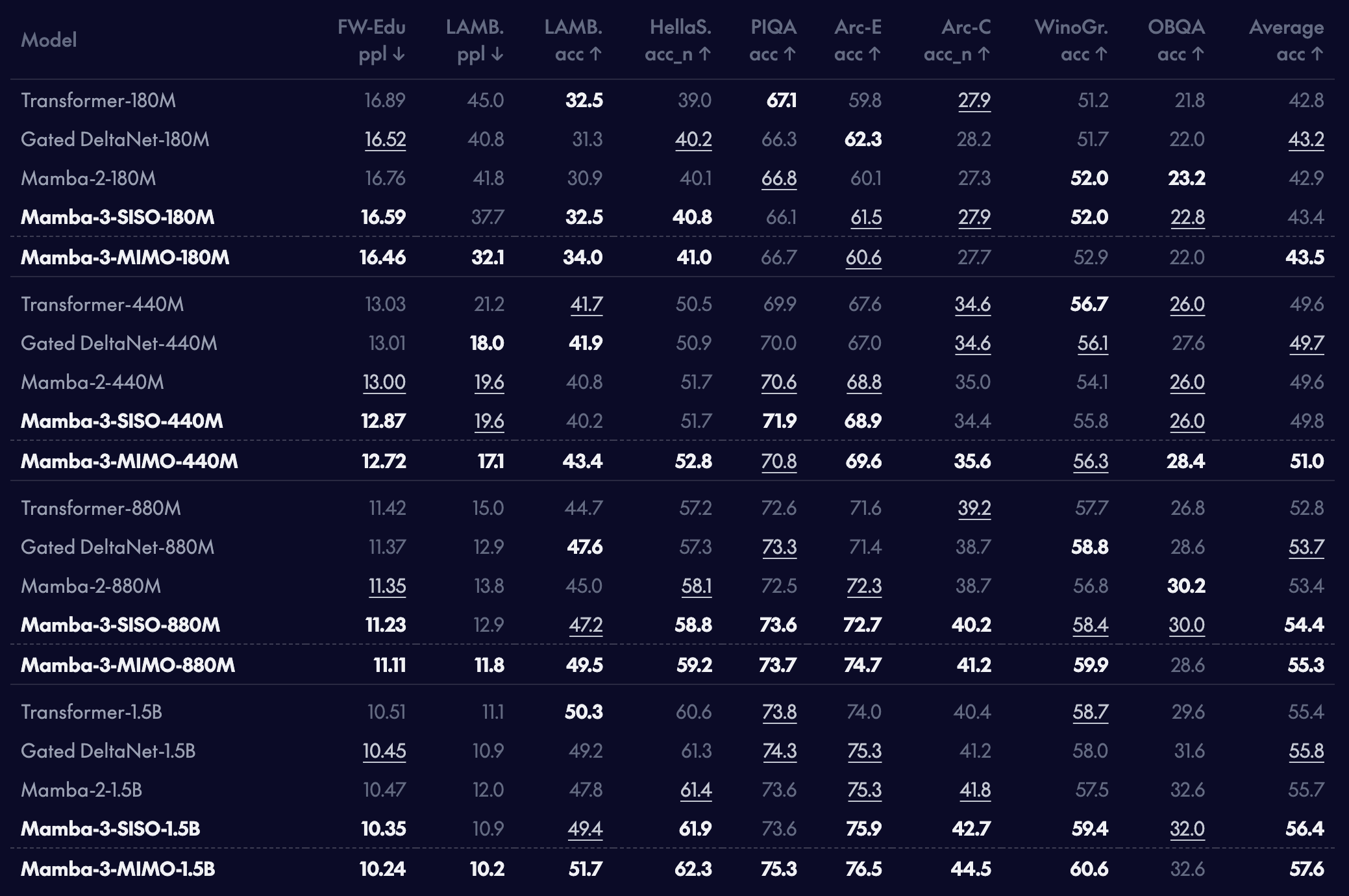
▲ Mamba-3와 다른 모델들의 언어 모델링 성능 비교. 다양한 벤치마크에서 Mamba-3가 기존 모델들을 앞서고 있습니다. (출처: Together AI)
AI 서비스 가격이 더 빨리 떨어질 수 있습니다
이 기술이 왜 중요할까요? AI 서비스 비용의 상당 부분은 GPU 메모리에서 나옵니다. ChatGPT가 긴 문서를 읽을 때 비싼 이유도 Transformer가 메모리를 많이 쓰기 때문입니다. 지금 ChatGPT의 100만 토큰 입력 비용은 약 3,300원인데, 이 비용의 핵심 원인이 바로 메모리입니다.
Mamba-3 같은 기술이 상용 AI에 적용되면, 같은 GPU로 2배 더 많은 사용자를 처리할 수 있어 AI 서비스 가격이 더 빨리 떨어질 수 있습니다. 이미 구글, Meta 등 대형 AI 기업들도 Mamba 같은 효율적 구조를 연구하고 있습니다.
Transformer를 완전히 대체하는 것은 아닙니다
다만 Mamba-3에도 약점은 있습니다. 정보 검색(특정 문장을 정확히 찾아내는 작업)에서는 여전히 Transformer가 더 뛰어납니다. Transformer의 '어텐션(주의 집중, AI가 중요한 부분에 집중하는 기능)' 메커니즘은 방대한 문서에서 특정 내용을 정확히 뽑아내는 데 탁월합니다.
연구팀도 이를 인정하며, "미래에는 Mamba 같은 효율적 구조와 Transformer의 강력한 검색 능력을 결합한 하이브리드 구조가 최적"이라고 밝혔습니다. 문서를 훑어보는 작업은 Mamba-3가, 정확한 검색이 필요한 부분은 Transformer가 담당하는 구조입니다.
개발자라면 지금 바로 사용할 수 있습니다
Mamba-3는 Apache 2.0 라이선스로 무료 공개됐으며, 깃허브(스타 1만 7,400개)에서 바로 사용할 수 있습니다.
# PyTorch 설치 후 실행
pip install mamba-ssm --no-build-isolation현재 사전학습된 모델은 Mamba-1(최대 2.8B)과 Mamba-2(최대 2.7B)가 Hugging Face에 공개돼 있으며, Mamba-3 사전학습 모델은 준비 중입니다. NVIDIA GPU와 CUDA 11.6 이상이 필요합니다.
이 연구의 의미는 명확합니다. AI의 핵심 기술이 더 이상 하나가 아니라는 것입니다. Transformer 독주 체제에 경쟁이 시작됐고, 그 혜택은 AI 서비스를 쓰는 모든 사용자에게 더 빠르고 더 저렴한 AI로 돌아올 것입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기