멀티 에이전트(Multi-Agent) 실패율 87% — UC 버클리 MAST 연구의 14가지 원인 분석
UC 버클리가 MetaGPT 등 멀티 에이전트 시스템 7종의 실행 기록 1,642건을 분석한 결과 실패율이 최대 87%였습니다. MAST 분류 체계로 정리한 14가지 실패 유형과 성공률을 높이는 해결책을 소개합니다.
멀티 에이전트(Multi-Agent) 시스템은 여러 AI 에이전트를 팀처럼 협업시키는 기술입니다. 그런데 UC 버클리 연구팀이 LLM 기반 멀티 에이전트 1,642건의 실행 기록을 분석한 결과, 현실은 기대와 정반대였습니다. 인기 있는 멀티 에이전트 프레임워크 7종의 실패율이 41%에서 최대 86.7%에 달했고, 실패 원인은 크게 14가지로 분류됐습니다. AI 에이전트를 업무에 도입하려는 분이라면 반드시 알아야 할 연구입니다.
멀티 에이전트 시스템이란 무엇이고, 왜 실패율이 높을까
요즘 AI 업계의 가장 뜨거운 트렌드 중 하나는 '멀티 에이전트 시스템(Multi-Agent System)'입니다. AI 에이전트 하나가 코드를 짜고, 다른 하나가 검토하고, 또 다른 하나가 테스트하는 — 마치 개발팀처럼 AI들이 협업하는 방식입니다. AI 기초부터 배우고 싶다면 무료 학습 가이드에서 에이전트 개념을 먼저 확인해보시기 바랍니다.
그런데 UC 버클리의 Ion Stoica(Databricks·Anyscale 공동 창업자), Matei Zaharia(Databricks 공동 창업자), Joseph Gonzalez 교수 등 AI 분야 최고 권위자들이 모여 이 방식이 정말 효과적인지 대규모 실험을 했습니다. 결과는 충격적이었습니다.
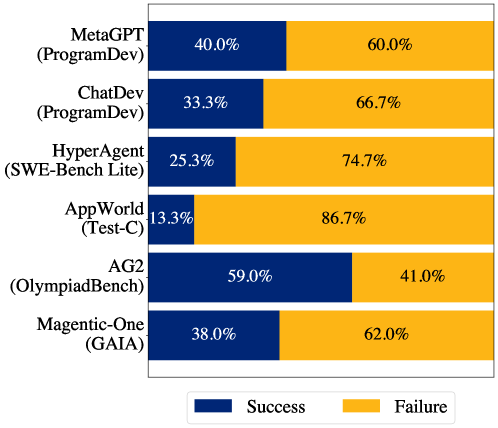
위 차트가 보여주듯, 테스트한 6개 시스템 모두 실패율이 41%를 넘었습니다. 가장 나쁜 경우(AppWorld)는 86.7%가 실패했고, 가장 나은 경우(AG2)조차 41%가 실패했습니다. MetaGPT는 60%, ChatDev는 66.7%, Magentic-One은 62%의 실패율을 기록했습니다.
MAST 분류 체계 — LLM 에이전트 실패의 14가지 패턴
연구팀은 MetaGPT, ChatDev, HyperAgent, AppWorld, AG2, Magentic-One, OpenManus 등 7개 프레임워크(AI 에이전트 협업 도구)에서 발생한 1,642건의 실행 기록을 전문가 6명이 직접 분석했습니다. 그 결과 실패 원인을 3가지 대분류, 14가지 세부 유형으로 정리한 'MAST'(Multi-Agent System Failure Taxonomy) 분류 체계를 만들었습니다.
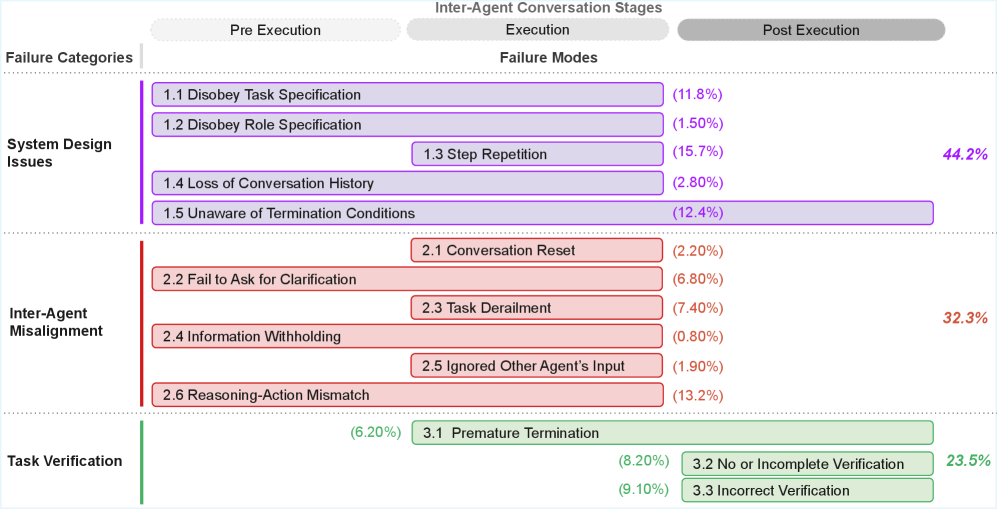
🔵 1번 카테고리: 시스템 설계 문제 (전체 실패의 44.2%)
AI 에이전트가 지시를 무시하거나 같은 일을 반복하는 등, 시스템 자체의 구조적 문제입니다.
• 같은 작업을 계속 반복 — 15.7%로 가장 흔한 실패. 에이전트가 한 번 한 일을 또 하고 또 합니다
• 언제 끝내야 하는지 모름 — 12.4%. 작업이 끝났는데도 멈추지 않고 계속 돌아갑니다
• 시킨 일을 안 함 — 11.8%. 주어진 과제를 무시하고 다른 일을 합니다
• 대화 기록을 잃어버림 — 2.8%. 앞에서 논의한 내용을 까먹습니다
• 역할을 무시함 — 1.5%. '검토자' 역할인데 코드를 직접 고쳐버립니다
🔴 2번 카테고리: 에이전트 간 소통 실패 (전체 실패의 32.3%)
AI 에이전트들끼리 대화할 때 정보가 꼬이거나 의견을 무시하는 문제입니다.
• 생각과 행동이 다름 — 13.2%. '이렇게 하겠다'고 말해놓고 실제로는 다른 일을 합니다
• 주제에서 벗어남 — 7.4%. 본래 과제와 상관없는 방향으로 대화가 흘러갑니다
• 확인을 안 함 — 6.8%. 모호한 지시를 받았는데 되묻지 않고 멋대로 진행합니다
• 대화가 리셋됨 — 2.2%. 앞서 나눈 대화 맥락이 갑자기 사라집니다
• 동료 의견 무시 — 1.9%. 다른 에이전트가 한 피드백을 완전히 무시합니다
• 정보를 숨김 — 0.8%. 알고 있는 정보를 다른 에이전트에게 전달하지 않습니다
🟢 3번 카테고리: 결과 검증 실패 (전체 실패의 23.5%)
작업을 마쳤는데 결과가 맞는지 확인을 제대로 하지 않는 문제입니다.
• 틀린 검증 — 9.1%. 결과를 확인했는데 잘못된 판단을 내립니다
• 검증 자체를 안 함 — 8.2%. 결과를 확인하는 단계를 아예 건너뜁니다
• 너무 일찍 끝냄 — 6.2%. 작업이 덜 끝났는데 '완료'라고 보고합니다
AI 에이전트 프레임워크별 실패 유형 비교
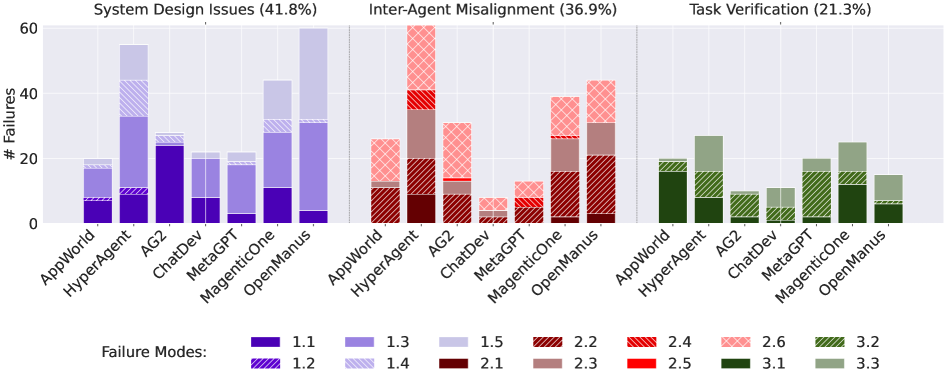
흥미로운 점은 각 시스템마다 취약한 부분이 달랐다는 것입니다. HyperAgent는 시스템 설계 문제가 압도적으로 많았고, AG2는 에이전트 간 소통 실패가 가장 큰 문제였습니다. OpenManus는 세 가지 카테고리가 고르게 분포했습니다.
이는 '멀티 에이전트'라고 다 같은 게 아니라, 어떤 구조로 에이전트를 조합하느냐에 따라 완전히 다른 종류의 문제가 발생한다는 뜻입니다.
GPT-4o vs Claude — LLM 모델별 멀티 에이전트 실패 패턴 차이
연구팀은 GPT-4o, Claude 3.7 Sonnet, Qwen2.5-Coder-32B, CodeLlama-7b 네 가지 AI 모델을 같은 시스템에 넣어 비교했습니다. 모델이 바뀌면 같은 시스템이라도 실패 패턴이 달라졌습니다. 즉, 시스템 설계와 AI 모델 선택 모두 중요하다는 결론입니다.
멀티 에이전트 성공률 높이는 해결책 — 역할 명확화 +9.4%, 결과 검증 +15.6%
연구팀은 실패를 줄일 수 있는 구체적인 방법도 실험했습니다.
실험 결과 (ChatDev 기준):
• 각 에이전트의 역할을 더 명확하게 지정 → 성공률 +9.4% 향상
• 작업 완료 후 결과 검증 단계를 추가 → 성공률 +15.6% 향상
사람으로 치면, "네가 무슨 일을 하는 사람인지 정확히 알려주고" + "일 끝나면 반드시 결과를 확인하라"는 간단한 지시만으로 성공률이 크게 올랐습니다.
해커뉴스 개발자들의 멀티 에이전트 실전 경험
이 논문은 해커뉴스에서 73포인트와 33개의 댓글을 받으며 활발한 논의가 이어졌습니다.
한 개발자는 "Auto-GPT를 파이썬 30줄로 대체했더니 10분 걸리던 작업이 10초로 줄고, 비용은 100분의 1이 됐다"고 공유했습니다. 여러 에이전트를 돌리는 대신, 간단한 코드로 순서대로 처리하는 게 오히려 낫다는 경험담입니다.
또 다른 개발자는 "비싼 AI 모델 하나가 전체를 관리하고, 싸고 작은 AI 모델 여러 개가 세부 작업을 맡는 구조"에서 성공했다고 했습니다. 모든 에이전트를 같은 수준의 AI로 돌릴 필요가 없다는 뜻입니다.
핵심 합의는 이것이었습니다: "95% 이상의 신뢰도가 필요하면, AI 에이전트 간 조율보다 일반 프로그래밍 코드로 흐름을 제어하는 것이 낫다."
AI 에이전트 도입 시 실패를 줄이는 체크리스트
① 에이전트 1개로 충분한지 먼저 확인하기
여러 에이전트가 반드시 좋은 것은 아닙니다. 하나의 AI에게 단계별로 지시하는 것이 더 안정적일 수 있습니다.
② 역할을 아주 구체적으로 정의하기
"코드를 검토해"보다 "보안 취약점만 찾아서 심각도와 해결 방법을 보고해"처럼 구체적으로 지시하면 성공률이 올라갑니다.
③ 반드시 결과 검증 단계를 넣기
작업이 끝났다는 AI의 보고를 그대로 믿지 말고, 결과를 확인하는 별도 단계를 추가하는 것이 +15.6% 효과가 있었습니다.
④ 비싼 AI + 저렴한 AI 조합 고려하기
Claude Opus 같은 고성능 모델이 전체를 관리하고, Haiku 같은 경량 모델이 단순 반복 작업을 맡는 구조가 비용 대비 효과적입니다.
MAST 연구 데이터와 코드 — 오픈소스 공개
연구팀은 분석에 사용한 데이터와 코드를 모두 오픈소스로 공개했습니다.
• 논문: arXiv에서 전문 읽기
• 코드: GitHub 저장소 (스타 350개)
• 데이터셋: HuggingFace에서 1,000건 이상의 주석 달린 실행 기록 다운로드 가능
AI 에이전트를 직접 개발하거나, 사내 업무에 멀티 에이전트 구조를 도입하려는 분들에게는 '어디서 실패할 가능성이 높은지'를 미리 파악할 수 있는 귀중한 자료입니다.
AI 에이전트와 자동화에 대해 더 알고 싶다면 무료 학습 가이드에서 기초부터 실전까지 단계별로 배울 수 있습니다.