AI가 시험 93점 맞더니 새 시험에선 13점 — 82개 AI를 분석한 연구가 AGI 환상을 깨뜨렸습니다
ARC-AGI 벤치마크 3개 버전에서 82개 AI 시스템을 분석한 첫 대규모 연구가 나왔습니다. AI는 쉬운 시험에서 93점을 맞지만 어려운 시험에선 13점으로 추락하고, 사람은 모든 버전을 100% 풀었습니다. AI의 추론 능력은 진짜 사고가 아니라 암기에 가깝다는 결론입니다.
AI가 똑똑해지고 있다는 뉴스, 매일 나옵니다. 벤치마크 점수가 90점을 넘었다, 사람을 이겼다 — 이런 기사를 보면 '곧 AI가 사람처럼 생각하겠구나' 싶습니다. 그런데 시험 문제를 조금만 바꾸면 AI 점수가 93점에서 13점으로 추락한다는 사실, 알고 계셨습니까?
이번에 나온 연구 "The ARC of Progress towards AGI"는 82개 AI 시스템을 한꺼번에 분석한 최초의 대규모 조사입니다. 결론은 충격적입니다 — AI는 문제를 '이해'하는 게 아니라 '외우고' 있었습니다.
ARC-AGI가 뭔가요? — AI의 '진짜 머리'를 테스트하는 시험
ARC-AGI는 AI의 추론 능력(새로운 문제를 보고 스스로 규칙을 찾아내는 능력)을 측정하는 벤치마크입니다. 일반 AI 시험과 다른 점은 암기로는 절대 풀 수 없다는 것입니다. 색깔 격자판을 보여주고 "이 패턴의 규칙이 뭔지 파악해서 빈칸을 채워라"라고 묻습니다.

▲ ARC-AGI-2 문제 예시. 왼쪽의 입력→출력 패턴을 보고 규칙을 파악한 뒤, 오른쪽 물음표에 답을 맞춰야 합니다. 사람은 대부분 2번 이내에 풀지만, 최고 성능 AI도 24%만 맞혔습니다.
테슬라 AI 출신 프랑수아 숄레와 Zapier 공동창업자 마이크 눕이 만들었고, 총 상금 12만 5천 달러(약 1억 7천만 원) 규모의 대회가 매년 열립니다. 2025년 대회에는 1,455개 팀이 참가했습니다.
93점 → 69점 → 13점 — 시험이 어려워지면 AI는 무너집니다
연구팀이 발견한 핵심은 이것입니다. ARC-AGI 시험에는 3개 버전이 있는데, 버전이 올라갈수록 AI 점수가 2~3배씩 떨어집니다.
AI 모델별 점수 변화 (버전 1 → 버전 2)
| AI 모델 | 쉬운 시험 (v1) | 어려운 시험 (v2) | 하락폭 |
|---|---|---|---|
| Gemini 3 Deep Think | 96.0% | 84.6% | ▼11.4%p |
| Claude Opus 4.6 | 93.0% | 68.8% | ▼24.2%p |
| GPT-5.2 Pro | 90.5% | 54.2% | ▼36.3%p |
| Gemini 3 Flash | 84.7% | 33.6% | ▼51.1%p |
| 👤 사람 | 100% | 100% | 변화 없음 |
그리고 가장 최신 버전인 ARC-AGI-3(게임처럼 직접 조작하면서 규칙을 찾아야 하는 인터랙티브 방식)에서는 최고 AI가 겨우 12.58%를 기록했습니다. 사람은 1,200명 이상이 참여해 3,900개 이상의 게임을 완료했고, 성공률은 역시 100%입니다.
핵심은 이겁니다 — 사람은 시험이 어려워져도 여전히 잘 풀지만, AI는 문제 유형이 조금만 바뀌면 점수가 곤두박질칩니다.
돈을 390배 더 써도 사람을 못 이기는 이유
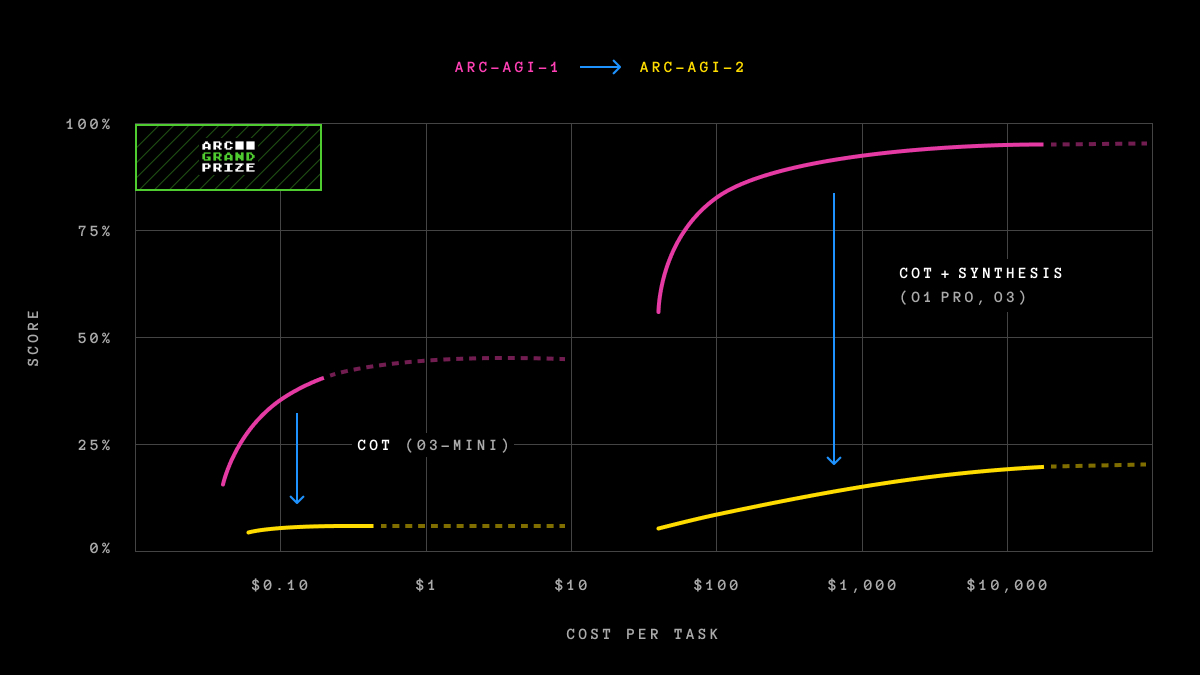
▲ 분홍색이 쉬운 시험(v1), 노란색이 어려운 시험(v2). 같은 비용을 써도 어려운 시험에서는 점수가 확 떨어집니다. AI가 돈을 쏟아부어도 '진짜 추론'은 안 되고 있다는 증거입니다.
좋은 소식도 있습니다. 문제 하나를 푸는 데 드는 비용은 1년 만에 390배 줄었습니다. OpenAI의 o3 모델이 문제당 4,500달러(약 600만 원)를 썼던 것이 GPT-5.2 Pro에서는 12달러(약 1만 6천 원)로 내려갔습니다.
하지만 여전히 사람이 문제를 푸는 비용(0.30~0.60달러)의 10~100배입니다. 연구팀은 이를 "AI의 추론은 지식에 묶여 있다(knowledge-bound)"고 표현했습니다. 쉽게 말하면, AI는 배운 것만 활용할 수 있고, 완전히 새로운 상황에서 규칙을 스스로 만들어내지 못한다는 뜻입니다.
82개 AI의 공통 실패 패턴 — '2~3단계 이상 조합'이 안 됩니다
연구팀은 82개 시스템을 세 가지 방식으로 분류했습니다.
모든 방식이 동일하게 무너졌습니다. 연구팀에 따르면, AI는 규칙을 2~3단계까지만 조합할 수 있습니다. 예를 들어 "빨간 칸을 오른쪽으로 옮겨라" + "초록 칸을 두 배로 키워라"는 각각 풀 수 있지만, 두 규칙을 동시에 적용하라고 하면 무너집니다. 사람은 이런 조합을 자연스럽게 처리합니다.
대회 우승팀도 24%를 넘지 못했습니다
2025년 ARC Prize 대회에서 1,455팀이 겨룬 결과, 1등 NVARC 팀의 점수는 24.03%에 불과했습니다. 수십만 개의 합성 데이터를 만들어 훈련한 결과입니다. 2등 ARChitects(16.53%), 3등 MindsAI(12.64%)도 사정은 비슷했습니다.
가장 주목받은 논문은 7백만 개 파라미터(ChatGPT의 수만 분의 1 크기)짜리 초소형 모델로 v1에서 45%를 달성한 "Tiny Recursive Model"이었습니다. 거대한 모델보다 작지만 영리한 모델이 더 효율적일 수 있다는 가능성을 보여주었습니다.
이 연구가 중요한 3가지 이유
AI 기업들이 발표하는 90점 이상의 벤치마크 점수는 '익숙한 문제를 잘 푸는 것'이지, '새로운 상황에서 생각하는 것'이 아닙니다. 연구에 따르면 100개 미만의 문제로 테스트한 논문은 점수를 평균 70% 과대 보고하고 있었습니다.
AI가 시험 점수를 올리는 속도는 빠르지만, 시험 유형이 바뀌면 처음부터 다시 시작입니다. 사람처럼 "처음 보는 문제도 생각해서 푸는" 능력은 아직 구현되지 않았습니다.
연구팀도 인정한 사실입니다 — AI가 이미 알고 있는 영역에서는 놀라운 성과를 냅니다. "충분한 학습 데이터가 있고, 답이 맞는지 확인할 수 있는 분야"는 AI가 자동화할 수 있습니다. 다만 그것을 '생각한다'고 부르기는 어렵습니다.
AI를 쓸 때 기억할 것
이 연구의 실용적 교훈은 명확합니다. AI는 '익숙한 작업의 자동화 도구'로 쓸 때 최고이고, '처음 보는 문제를 해결하는 두뇌'로 기대하면 실망합니다.
보고서 작성, 데이터 정리, 코드 작성, 번역 — 이런 작업에서 AI는 사람보다 빠르고 정확합니다. 하지만 "이 데이터에서 아무도 발견하지 못한 패턴을 찾아줘"라는 요청에는 한계가 있습니다. AI에게 새로운 아이디어를 기대하기보다, AI가 잘하는 반복 작업을 맡기고 창의적 판단은 직접 하는 것이 현재로서는 가장 현명한 활용법입니다.
ARC-AGI 벤치마크를 직접 체험해보고 싶다면 ARC Prize 공식 사이트에서 문제를 풀어볼 수 있습니다. AI보다 훨씬 잘 풀리는 자신을 발견하게 될 것입니다.
관련 콘텐츠 — Easy클코로 AI 시작하기 | 무료 학습 가이드 | AI 뉴스 더보기